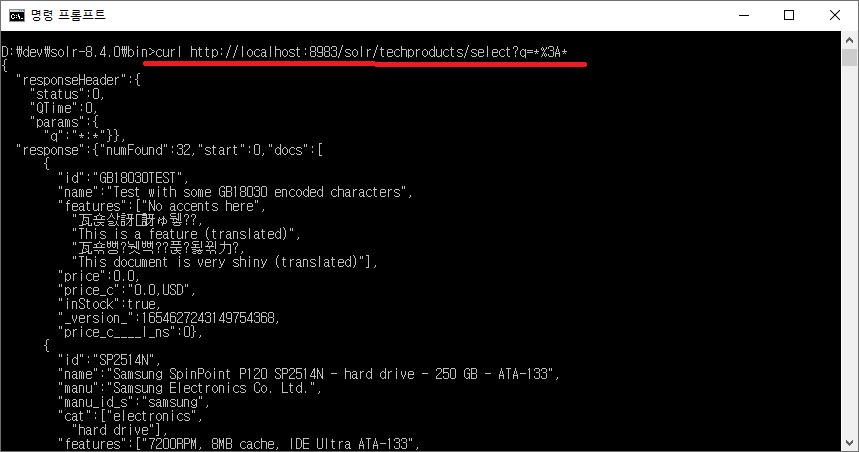
앞서서 실행해 본 호텔 예약 챗봇 예제를 Intent와 Entity의 두 용어(메뉴)를 중심으로 정리하였다.
여기에서는 이 두 가지가 어떻게 구성되어 있는지(만드는지) 간단하게 정리하였다.
이 문서는 Dialogflow로 챗봇을 만드는 방법이 아니라 전체 개념과 몇 가지 용어에 익숙해지기 위해
앞서서 실행해 본 호텔 예약 챗봇 예제를 구성하는 요인에 대해서 정리한 문서이다.
Entity
먼저, Entity는 데이터 베이스의 데이터 타입와 비슷한 개념으로 개체 종류를 의미한다.
Entities 메뉴를 실행해 보면 [CUSTOM] 탭에 @room이라는 Entity가 등록되어 있다.
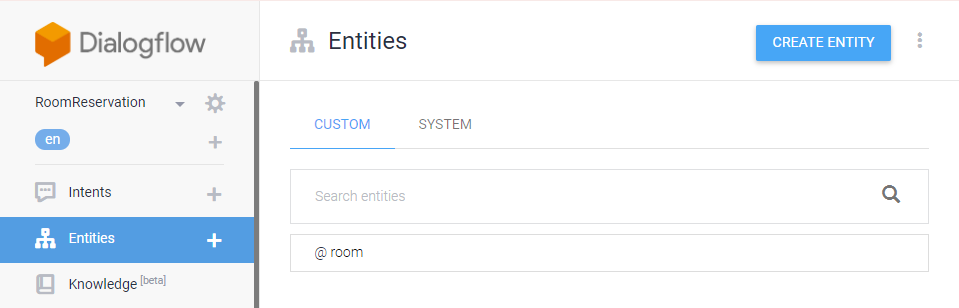
@room를 클릭하면 A, B, C가 등록되어 있다.
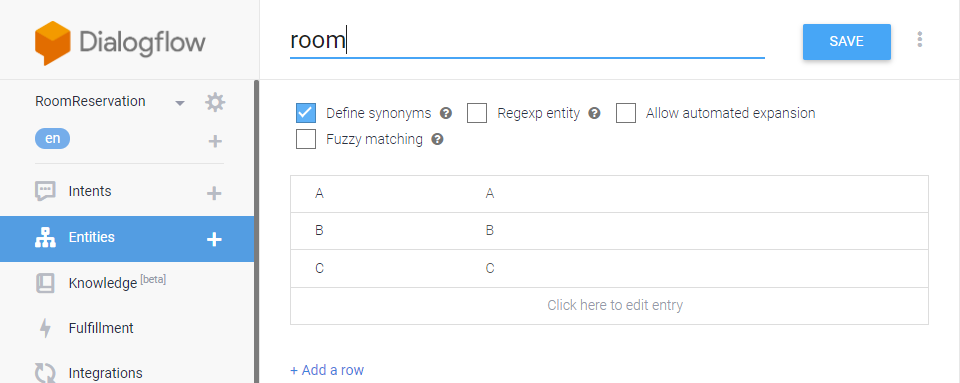
A, B, C는 싱글룸, 더블룸, 스위트룸 같은 호텔 방 종류가 room이라는 개체(Entity)로 정의되어 있다.
하단의 [Add a row]를 눌러서 추가할 수 있다.
다시 Entities 메뉴를 실행하고, 이번에는 [SYSTEM] 탭을 선택한다.
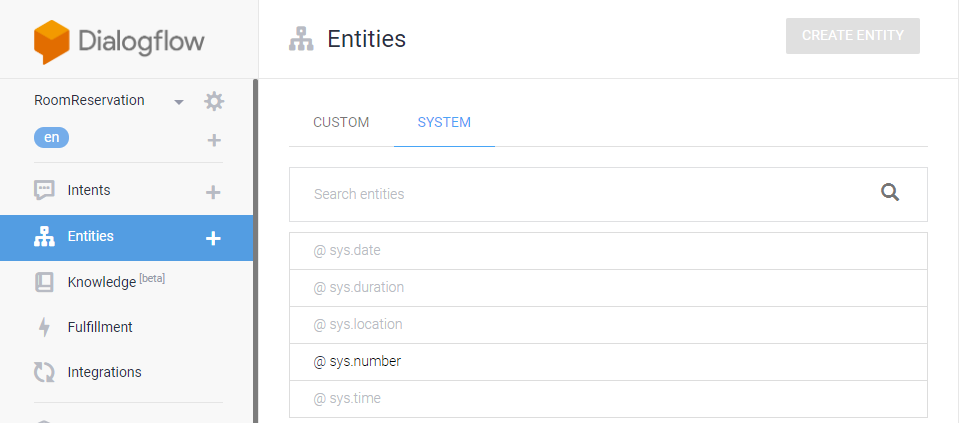
[CUSTOM]은 사용자가 등록한 개체고,
[SYSTEM]은 Dialogflow가 제공하는 것으로 숫자(number), 날짜(date), 위치(location) 등의 개체들이 정의 되어 있다.
Intent
왼쪽 메뉴에서 Intents를 선택한다.
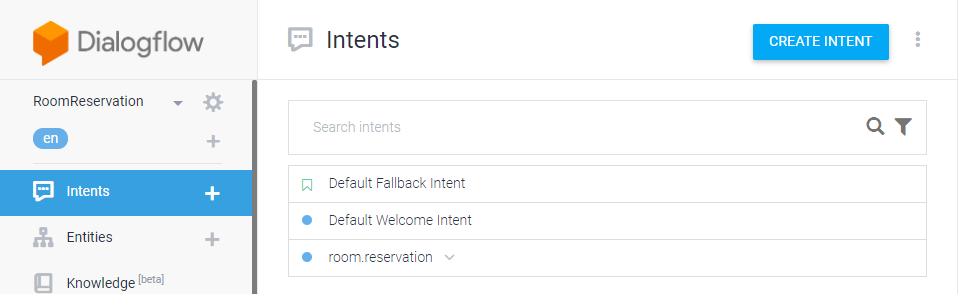
Dialogflow가 기본 제공하는 2개 intent와 가져오기로 추가된 1개의 intent가 있다.
1. Default Fallback Intent
이 리스트에서 [Default Fallback Intent]를 클릭해 보면,
대부분 빈 내용이고 하단에 있는 [Response](대답)에 무슨 말인지 모르겠으니 다시 말해달라는 문장이 다양하게 적혀있다.
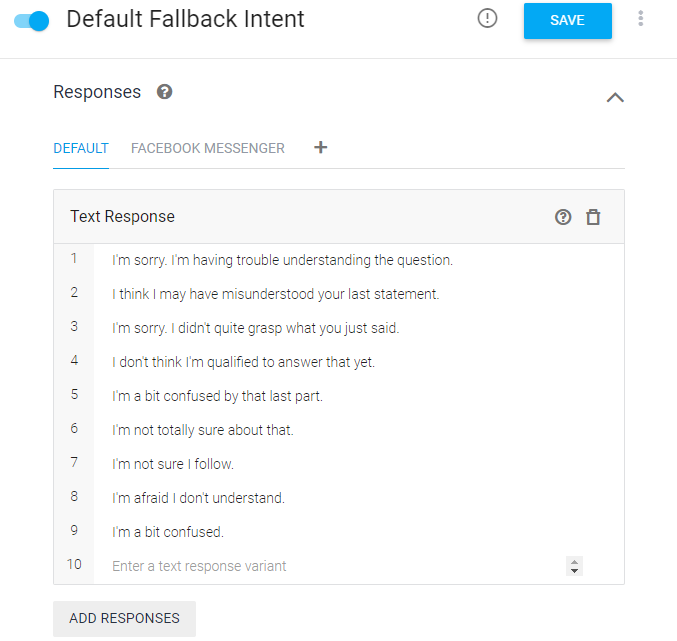
말 그대로 고객의 말을 못 알아 들었을 때,
사용하는 문장들로 하나만 사용하면 지겨워서(?) 여러 가지를 등록한다고 한다.
2. Default Welcome Intent
Intents 리스트에서 [Default Welcome Intent]를 선택하면,
Training phrases(학습문장)과 Response(대답)만 채워져 있고 다른 부분은 비어있다.
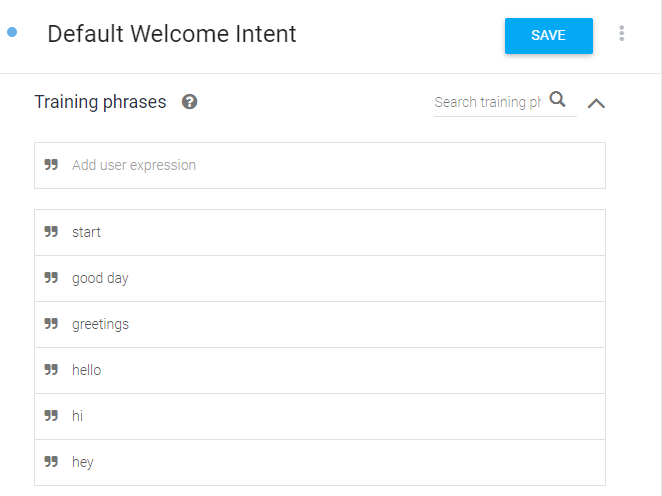
[Add user expression]로 표시된 입력창에서 문장을 추가 할 수 있다.
Training phrases(학습문장)은 고객이 입력하는 문장으로,
고객이 이상과 같이 입력하면(Training phrases), 다음과 같이 Response(대답)하게 된다.
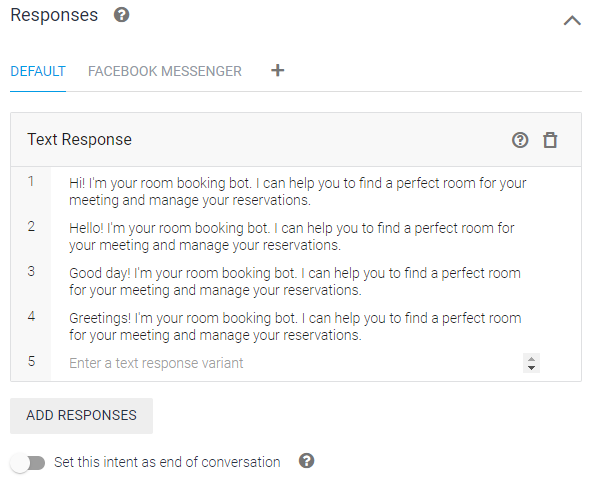
Response(대답)에서는 [Enter a text response variant]에 새로운 문장을 입력해서 추가한다.
내용을 추가하거나 수정 한 뒤에는 우측 상단의 [SAVE]버튼을 눌러서 저장한다.
3. room.reservation
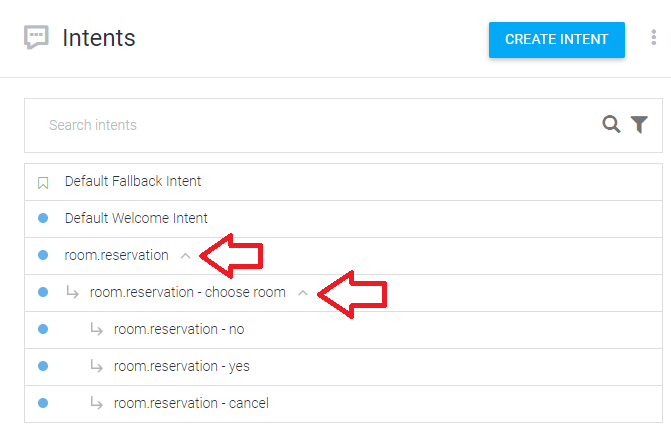
가장 중요한 Inent인 실제 예약 (room.reservation)을 클릭해서 앞서의 Inent처럼 상세 내용을 보거나,
∧와 ∨ 아이콘을 눌러서 하위 Inent을 확인 할 수 있다.
room.reservation 하위에 4개의 Intent가 더 있다.
이 구조를 다르게 표현하면 다음과 같다.
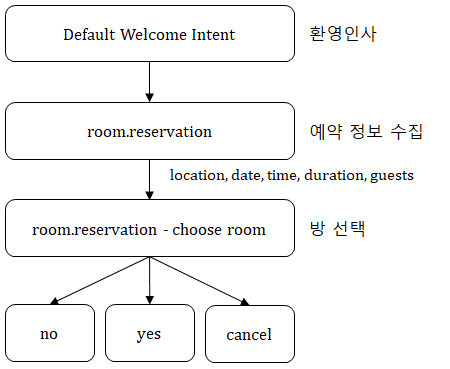
예약에 필요한 위치(location), 날짜(date) 등의 정보를 대화를 통해 수집하고 (room.reservation),
호텔 방 종류를 선택하면 (room.reservation - choose room)
예약이 맞는지 확인하고 예약(yes)거나 취소(no, cancel)하는 구조이다.
방 선택과 예약 확인은 상세 내용을 보면 쉽게 이해 할 수 있지만
정보를 수집하기 위해 대화하는 과정은 이 예약 챗봇의 핵심으로 조금 복잡하고 어려울 수 있다.
리스트에서 room.reservation를 선택하면,
핵심 부분이라 제법 많은 내용들이 출력되는데,
전체 구조는 Contexts, Event, Training phrases, Action and parameters, Responses, Fulfilment로 구성되어 있다.
이중에서 Event, Fulfilment는 여기에서 사용하지 안았다.
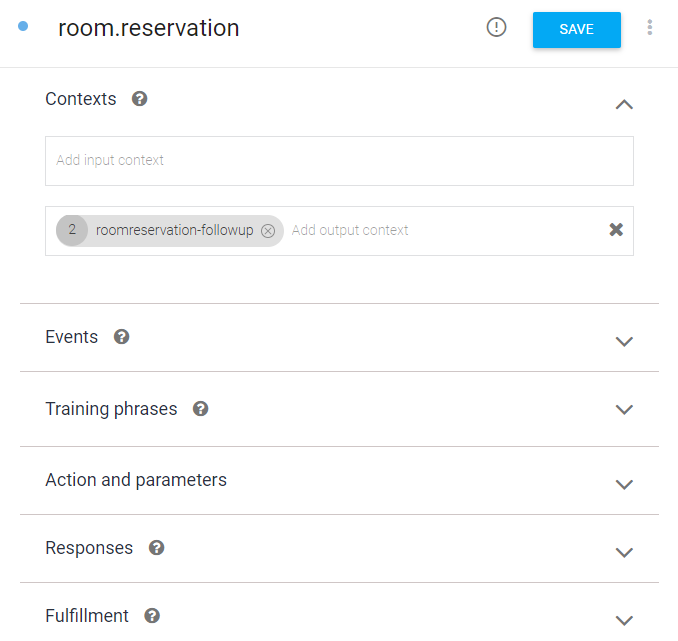
Contexts는 Intent의 순서들을 의미한다.
현재의 Intent를 실행하기 위해 먼저 실행해야 할 Intent와 (input context)
현재의 Intent를 실행한 뒤에 실행할 Intent(output context)을 지정한다.
즉, 앞서의 트리 구조를 지정하는 곳으로
예약 정보(room.reservation) 수집 전에는 먼저 실행할 Intent가 없고,
예약 정보가 수집되었으면 방선택(room.reservation - choose room) Intent을 실행한다.
(고객이 인사를 하면 환영인사 후에 실행 될 수 있고, 고객이 바로 예약을 진행 할 수 있다)
Training phrases(학습 문장)에는 예약과 관련 74개의 다양한 문장이 입력되어 있다.
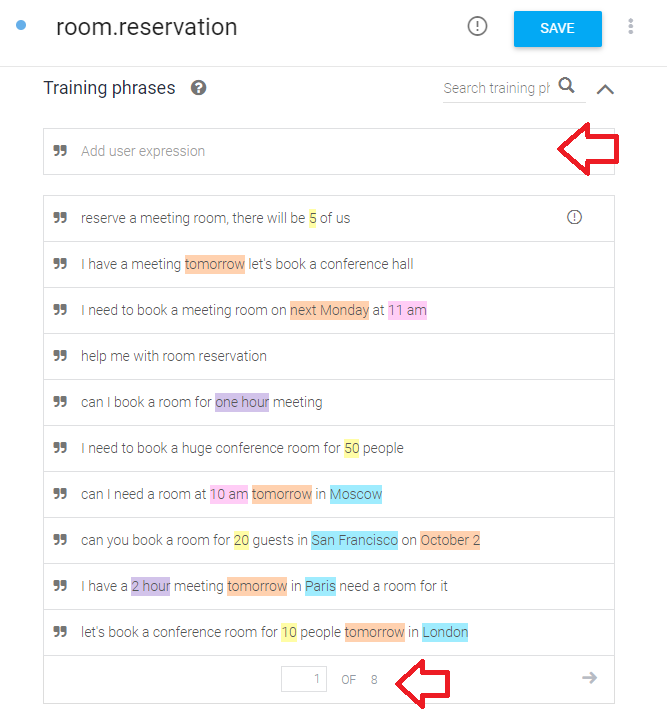
Training phrases(학습 문장)은 고객이 하는 말이고,
Responses(대답)는 챗봇이 하는 말을 의미한다.
환영인사(Default Welcome Intent)에서는 이 두 대화 문장만 있었지만,
대화를 통해 정보를 수집하기 위한 Action and parameters가 작성되었다.
tomorrow와 같은 색상이 있는 단어를 클릭하면, 그림과 같은 메뉴가 나타난다.
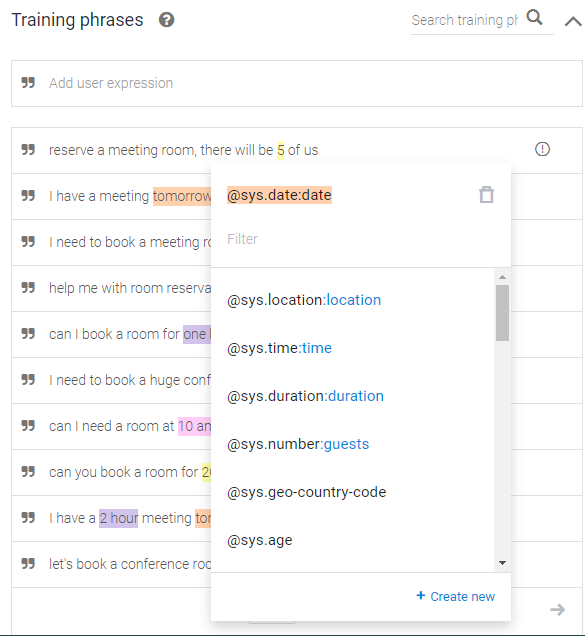
tomorrow는 날짜(date)로 지정되어 있다.
내일 회의가 있어서 회의실을 예약 할거야(I have a meeting tomorrow let's book a conference hall)란 문장에서
내일(tomorrow)이 예약에 필요한 핵심 키워드로 추출되고, 내일(tomorrow)은 날짜형으로 보관된다.
사람은 날짜를 인식할 수 있지만, 챗봇은 알 수 없기 때문에 이렇게 미리 지정해 둔다.
다음 주 월요일 11시에 예약할거야(I need to book a meeting room on next Monday at 11 am)에서는
다음 주 월요일(next Monday)과 11시(11 am)가 지정되어 있다.
다른 문장들도 이렇게 지정되어 있으며, 같은 색상은 같은 타입을 의미하고
이렇게 예약에 필요한 위치(location), 날짜(date), 시간(time), 체류기간(duration), 인원수(guests)를 수집한다.
참고: 개인적으로는 이 부분의 대화 양이 챗봇의 성능을 판단하는 기준이 되는 것 같다. 얼마나 많은 대화가 잘 정리되어 등록되는 냐에 따라서 사람(?) 같이 대화하는 것 같다.
이상처럼 수집되는 정보들에 대한 정의 / 종류를 지정하는 부분이 Action and parameters이다.
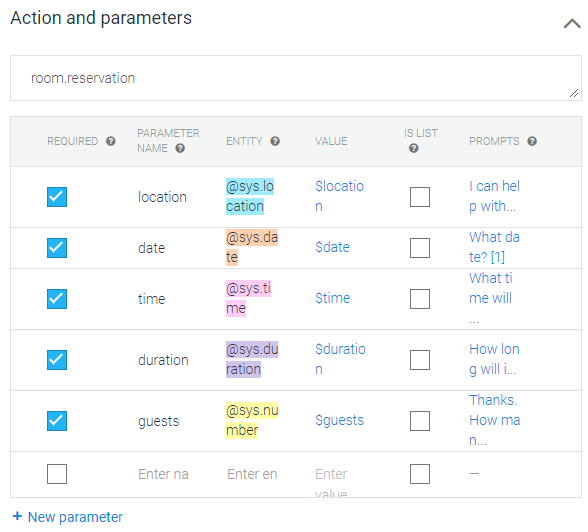
수집해야 할 위치(location), 날짜(date), 시간(time), 체류기간(duration), 인원수(guests)에 대한 속성을 ENTITY로 지정한다.
예로 인원수는 숫자(number)라고 지정하고,
3명과 같이 고객이 숫자를 입력하면 인원수를 입력한 것으로 처리한다.
해당 정보를 얻기 위해 챗봇이 해야할 질문은 PROMTS에 등록한다.
PROMTS를 클릭하면 다음과 같은 팝업창이 실행된다.
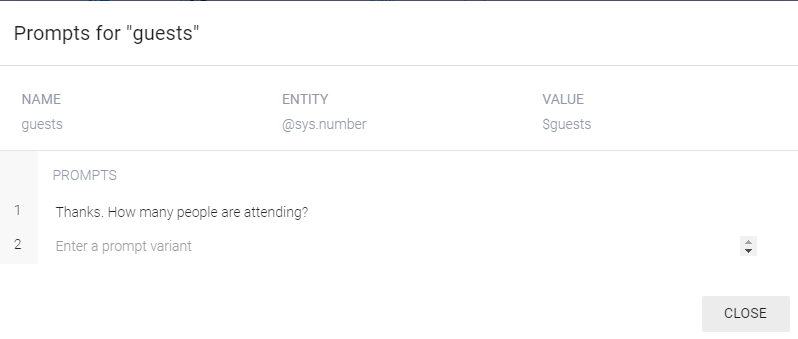
대화중에 3명이라고 이야기 한 경우에는 넘어가지만,
정보가 수집되지 않으면 "몇명이 묵을 겁니까?(How many people are attending)"라고 물어서 정보를 수집한다.
예약에 필요한 위치(location), 날짜(date), 시간(time), 체류기간(duration), 인원수(guests)를 수집했으면,
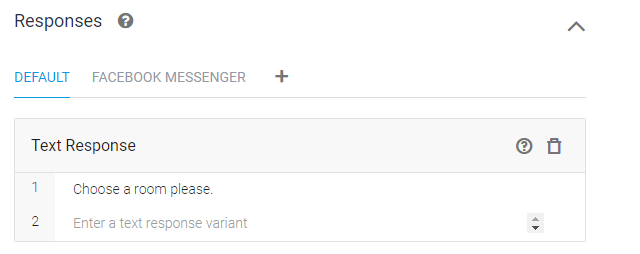
"방을 선택하세요(Choose a room please)"라고 응답하고(Resposes)
앞서 Context에서 output으로 지정한 [room.reservation - choose room] Intent로 넘어간다.
참고: 이상에서 PROMPT로 수집한 정보를 어떤 자료에서는 Intent로 만들어서 처리하기도 한다.
4. room.reservation - choose room
방 선택(room.reservation - choose room)은
그림처럼 room.reservation이 끝나면 실행되고(input context), 끝나면 확인 Intent(output context)가 실행된다.
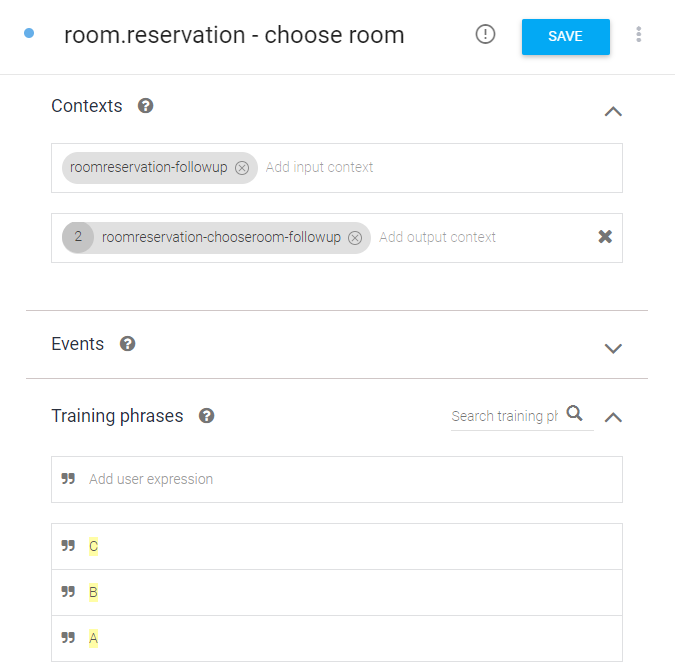
학습 문장(Training phrases)에는 A, B, C만 등록되어 있다.
방 종류를 의미하고, 이외의 문장을 입력하면 방 선택을 하라고 한다.
방 종류(A, B, C)가 노란색으로 표시 되어 있고,
Action and parameters에도 @room만 노란색으로 활성화 되어 있다.
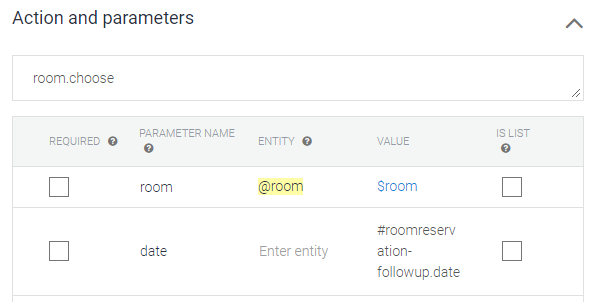
방 종류(A, B, C)는 @room 개체로 앞서서 Entity로 지정한 타입이라는 의미이다.
즉, 여기서는 방 종류에 대한 정보만 수집한다.
참고: room.reservation에서 Prompt로 처리한 것을 이렇게 Intent로 처리 할 수 있다.
방 종류를 선택하면 다음과 같이 수집한 정보를 채워서 고객에게 출력하고(Response)
다음 Intetnt로 넘어가 응답을 기다린다.
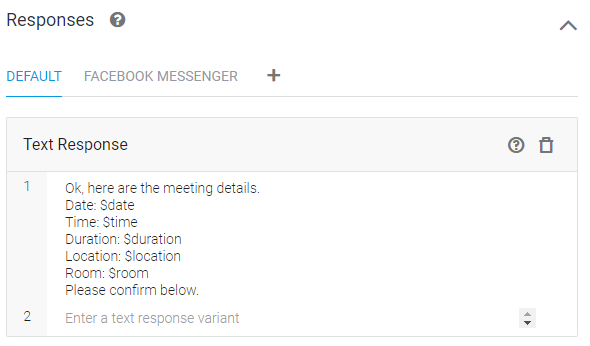
예약을 확인후 고객의 대답에 대한 처리는 정리하지 않는다.
이상과 같은 구조로 되어 있기 때문에 상세 내역을 확인하면 쉽게 이해 할 수 있을 것이다.
모두 고객의 예상되는 대답(Traning phrases)과 그것에 대한 챗봇의 대답(Response) 구조로 되어있다.
이 대화 속에 필요한 정보를 추출한다.
이상으로 챗봇 제작에 필요한 Entity와 Intent에 대해서 정리했다.
이 내용을 처음부터 하나 하나 생성하는 방법은
구글 Dialogflow 문서에서 [에이전트를 처음부터 빌드하기]를 따라하거나 다른 자료를 참고하면 된다.
이 문서는 만드는 방법이 아니라 전체 개념과 몇 가지 용어에 익숙해지기 위해 정리한 문서이다.
이 외에도 많은 예제가 제공되니 읽어보는 것이 도움이 될 것이다.
추가적으로 날짜를 yesterday(어제)를 입력해도 예약이 된다.
방 종류를 모르면 예약을 할 수 없다.
이외에도 많은 문제점이 있고,
이 문제점들은 프로그램과 연동이 필요한 것으로 Dialogflow만으로는 완벽한 챗봇을 만들 수 있는 것이 아니다.
챗봇을 만들기 위해 이제 첫 걸음을 내민 것이다.
'챗봇' 카테고리의 다른 글
| 5분만에 둘러보는 챗봇 만들기 - Dialogflow (0) | 2020.03.01 |
|---|