오픈 소스 Lucene(루씬)을 기반으로 하는
대표적인 검색엔진인 Solr(쏠라)와 Elasticsearch(엘라스틱서치)는 Lucene을 기반으로 하지만 사용법은 전혀 다르다.
특히 데이터 수집(색인-Indexing)에 있어서,
일반적인 문서 색인은 Solr가 쉽게 구현할 수 있고, 웹 로그와 같은 짧은 형태의 데이터는 Elasticsearch가 쉽게 구현할 수 있는 것 같다.
또, 검색(Search) 문법에 있어서 Solr는 Lucene의 문법을 그대로 따르고, Elasticsearch는 자신만의 문법을 구현한 차이가 있다.
이 두 가지 검색엔진의 차이를 이해하고,
둘 다 익히기 위해 예제를 만드는 중으로 세부 기능을 구현하는데 시간이 많이 걸려 (언제 끝날지...)
일단 먼저 기본적인 색인 / 검색 기능을 구현하고 설치 / 사용하는 방법을 정리한다.
Solr와 Elasticsearch예제는 각각 Github 에서 다운로드 받을 수 있다.
|
1. Solr 설치 |
먼저, Elasticsearch 예제 사용법을 정리한다.
예제는 그림과 같이 기존에 공유한 웹 프로젝트인 Project9에 검색 기능을 추가하는 형태로 작성했다.
Project9에 대한 설명은 기존 블로그에서 확인 할 수 있다.
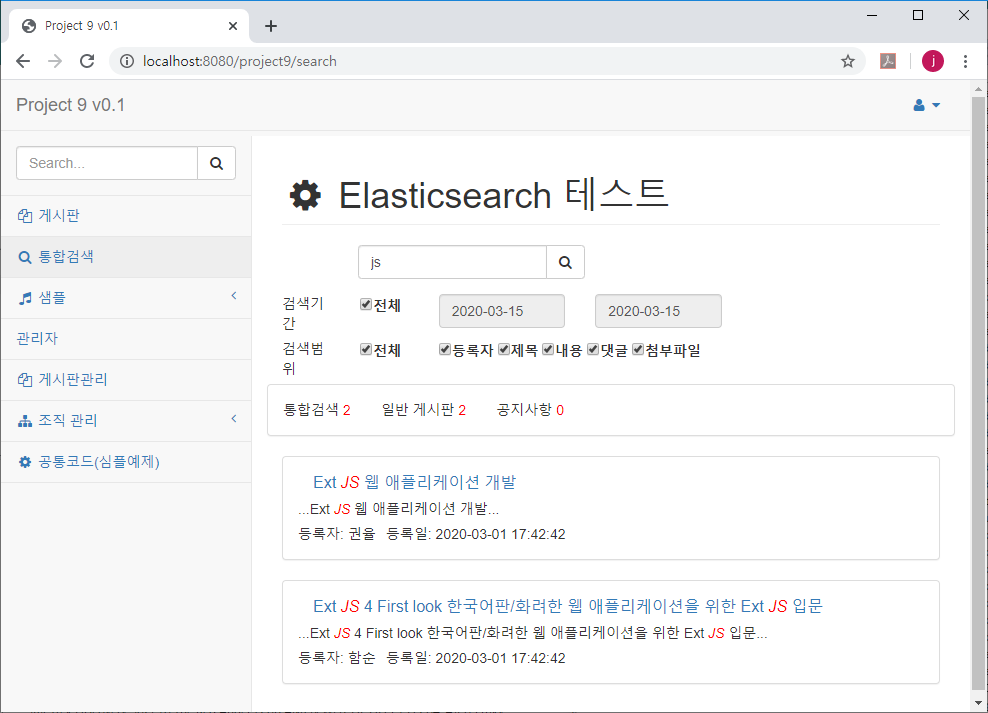
Project9의 게시판 데이터를 대상으로 하고,
공지사항과 일반 게시판의 게시판 종류를 데이터 종류로 구분해서 통합 검색 기능을 구현하였다.
설치 방법은 Elasticsearch설치와 Project9 설치로 구분된다.
Elasticsearch 설치
Project9 설치 소스 다운로드 및 설치 |
참고: Project9 설치는 기존 방식과 동일하기 때문에 여기에서 별도로 정리하지 않는다.
Elasticsearch 설치
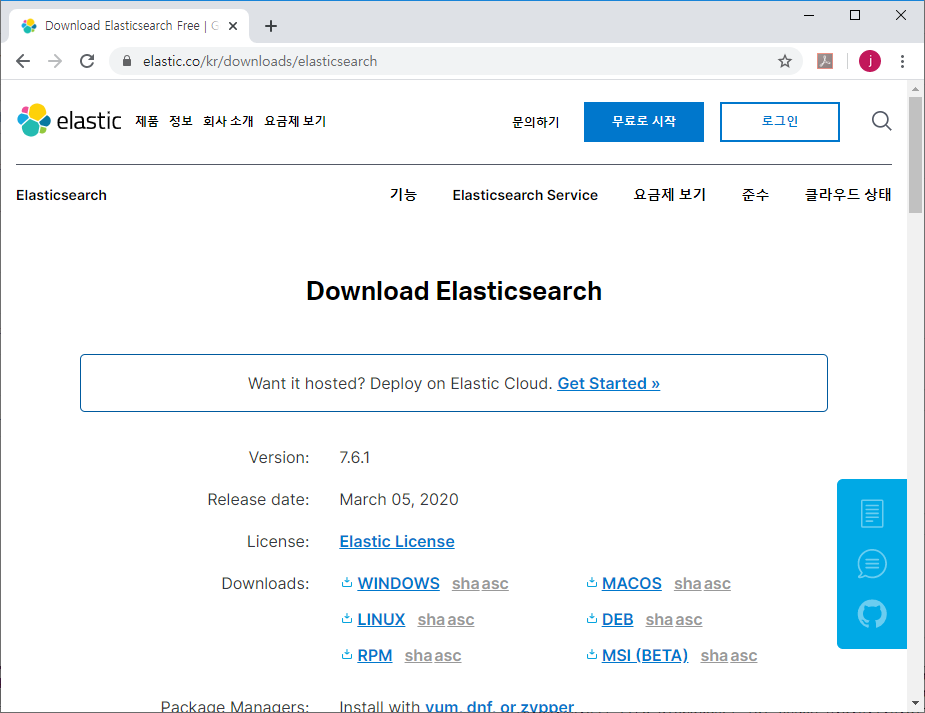
1. Elasticsearch 다운로드 및 설치
Elasticsearch 다운로드 사이트에서 운영체제에 맞는 압축 파일을 다운로드 받아서, 압축을 해제 한다.
2. Elasticsearch 실행
압축을 해제한 폴더에서 bin 폴더에 있는 elasticsearch.sh(Linux)나 elasticsearch.bat (윈도우)를 실행한다.
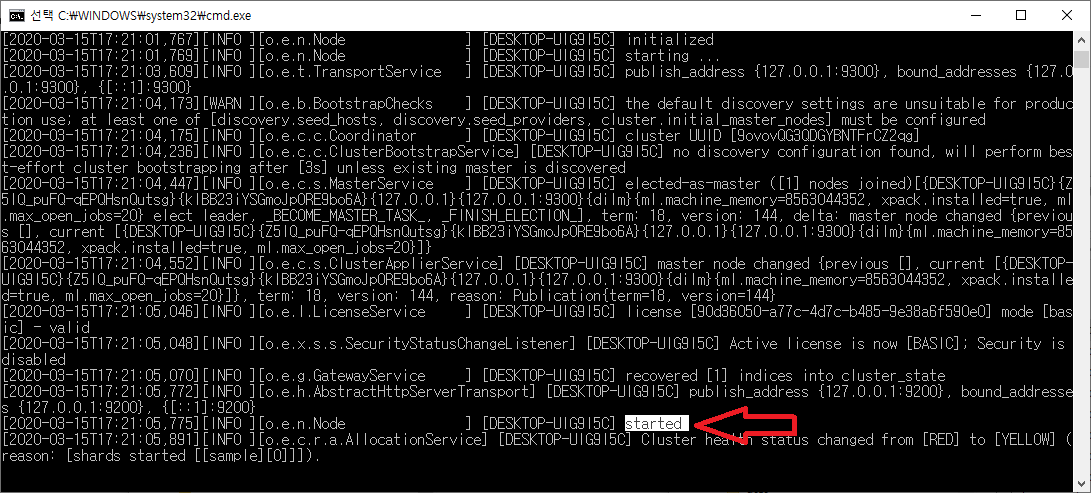
그림과 같이 started가 보이면 잘 실행 된 것이다.
주의: Elasticsearch는 JDK 1.8에서도 실행되지만, JDK 11 이상에서 실행하도록 강력하게 추천한다.
그리고, jdk 폴더에 JDK 13 버전이 포함되어서 배포된다.
JAVA_HOME이 설정되지 않은 경우, 이 JDK 13에서 실행된다.
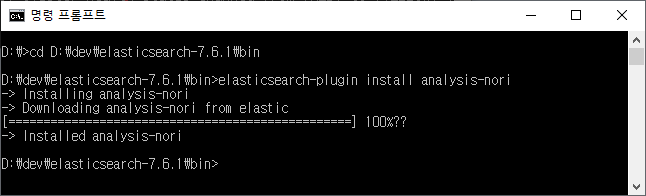
3. 형태소 분석기 설치
콘솔창(cmd)에서 Elasticsearch가 설치된 경로(bin)로 이동한 후,
다음 명령어를 실행해서 Elasticsearch에서 기본적으로 제공하는 형태소 분석기 nori를 설치한다.
elasticsearch-plugin install analysis-nori
4. 사전 복사
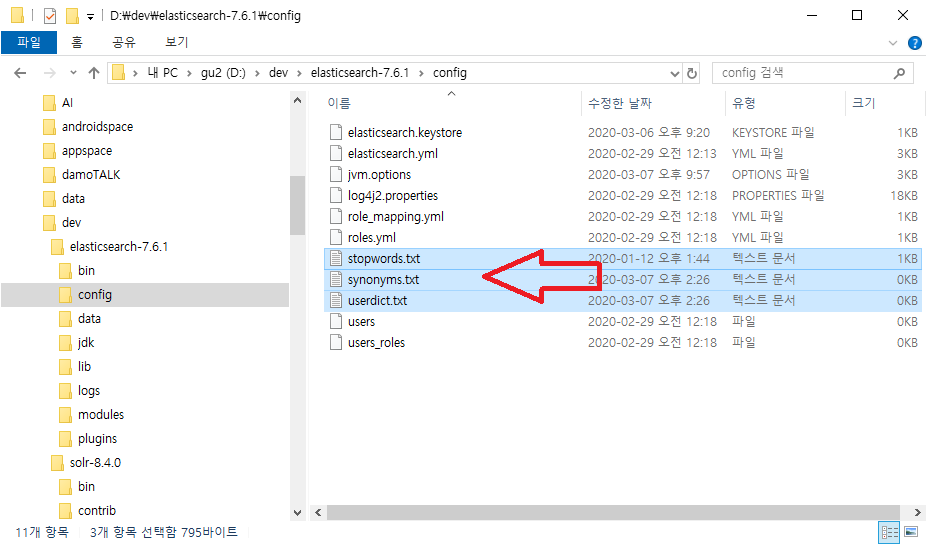
비었지만 나중에 사용할 사용자 사전(userdict.txt), 불용어 사전(stopwords.txt), 유의어 사전(synonyms.txt) 파일을 복사한다.
저장소 생성시 지정해 두었기 때문에 복사해야 한다.
사전 파일과 저장소 정보를 지정한 파일을 얻기 위해서는 Project9 Elasticsearch 예제 파일을 먼저 다운로드 받아야 한다.
문서 작성의 단계상 다음 단계에 하는 것으로 정리했지만, Project9의 Elasticsearch 예제 소스를 다음과 같이 다운로드 받는다.
또는, Eclipse에서 다운로드 받는 것이 편리하고, Eclipse로 git 소스를 다운로드 받는 것은 기존 블로그를 참고하면 된다.
git clone https://github.com/gujc71/Project9_es.git
다운 받은 Project9 소스 폴더에서 project9_es\elasticsearch에 있는 3개의 사전 파일을 [elasticsearch설치경로]/config 폴더에 복사한다.
5. 저장소(Index) 생성
앞서 설치한 형태소 분석기와 사전을 Elasticsearch에 인식시키기 위해 Elasticsearch를 다시 실행한다.
저장소 구성 정보를 저장한 index_board.json 파일이 있는 project9_es 설치 경로로 이동해서
다음 명령어를 실행한다.
curl -XPUT localhost:9200/project9 -d @index_board.json -H "Content-Type: application/json"
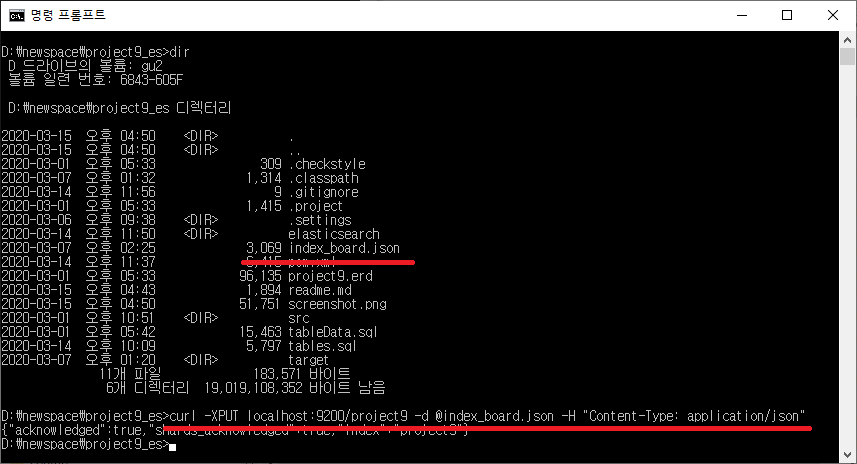
project9이라는 저장소(index)를 생성하고,
index_board.json 파일에 작성된 데로 저장 구조(Schema)를 생성한다.
Project9 설치
Project9의 설치는 기존에 공개한 웹 프로젝트로 기존 블로그에 정리되어 있다.
이 내용과 동일하고, Github 프로젝트 명만 project9이 아닌 project9_solr로 바꾸어 설치하면 된다.
그리고, 적당한 계정으로 로그인해서 [통합검색] 메뉴에서 다양한 검색 결과를 확인할 수 있다.
주의: Project9의 Elasticsearch 웹 예제를 실행하면, 1 분간격으로 데이터를 수집하도록 되어 있다.
Elasticsearch가 실행되어 있지 않으면 오류가 발생할 수 있고,
너무 빨리 통합 검색을 실행하면, 실행 결과가 없을 수 있다.
콘솔 창에서 Project9의 실행 로그 중에 데이터 수집 결과가 보이거나 조금 시간이 지난 뒤에 검색을 해야 한다.
이상으로 예제를 실행하는 방법을 정리하였고
데이터를 수집해서 색인하고, 색인한 데이터를 프로그램에서 조회하는 주요 부분에 대한 코드 정리는 다음 블로그에서 정리한다.
'서버 > 검색엔진' 카테고리의 다른 글
| 1. 검색엔진 실전 예제 - Solr 설치 (6) | 2020.03.15 |
|---|---|
| 2. 검색엔진 실전 예제 - Solr 주요 설정과 코드 (2) | 2020.03.15 |
| 4. 검색엔진 실전 예제 - Elasticsearch 주요 설정과 코드 (2) | 2020.03.15 |
| 검색 엔진, 챗봇 개발에 유용한 사전 (0) | 2020.02.16 |
| 1. Solr 예제 분석 - 설치 (1) | 2020.01.12 |