검색 서버를 구축 하려면 필요한 사항이 많지만, 가장 중요한 부분은 색인(Indexing)과 검색(Search)이다.
Elasticsearch에서는 색인과 검색을 모두 Java로 개발했다.
(Solr에서는 DIH - Data Import Handler를 이용하여 SQL문만 작성하여 색인한다.)
Logtash라고 데이터를 수집하는 별도의 프로그램이 있지만,
RDBMS의 부모 / 자식 관계, 첨부 파일 색인 처리에 어려움이 많아서 직접 개발하였다.
Logtash는 로그 데이터 수집에는 편리했지만 그 외에는 불편한 것이 많았다.
그래서 Log 가 붙은 것인지…
모든 기능을 아직 구현하지 않았고 (기약할 수 없지만 구현 중),
구현 방법을 모두 여기에 정리 할 수 없어서, 색인과 검색 개발에 관련된 몇 가지 주요한 사항만 정리한다.
주의: 용어나 옵션에 대한 상세한 설명을 정리하지 않기 때문에 Elasticsearch를 잘 모른다면 다음 내용이 어려울 수 있다.
|
1. Solr 설치 |
정리할 주요 내용은 다음 그림과 같다.

색인
색인 작업은 Elasticsearch 검색 서버가 처리하는 것이고,
색인과 관련해서 구현해야 하는 것은 데이터를 수집해서 Elasticsearch 검색 서버에 전달하는 것이다(IndexingCtr.java).
데이터 수집 작업은 수집한 데이터를 저장하는 공간(저장소-Index)에 대한 정의와 데이터를 수집하는 방법에 대한 정의로 구분된다.
색인할 데이터를 저장할 저장소(Index)에 대한 정의는 다운받은 Project9 프로젝트의 project9_es 폴더에 있는 index_board.json 파일에 있다.
Elasticsearch 설치 과정에서 이 파일을 실행해서 스키마를 정의하였다.
이것은 Json 계층 구조로 작성하고, 가장 최상위는 다음과 같다.
{
"settings": {
"number_of_shards" : 1,
"number_of_replicas": 0,
"index": {...}
},
"mappings": {
"properties": {...}
}
}
최상위는 저장소에 대한 설정(settings)과 구조(mappings)로,
설정은(settings) 샤드(number_of_shards) 개수, 복제(number_of_replicas) 개수, 색인(index) 규칙에 대해서 정의하고,
구조(mappings)는 속성키(properties) 하위에 색인해서 저장하는 필드들에 대해서 정의한다.
설정(settings)의 색인(index)에서는 형태소 분석기(노리-Nori) 사용에 대한 설정을 하고,
복합어 처리(decompound_mode), 필터, 불용어 처리 등을 지정한다.
이 중에서 nori_analyzer는 형태소 분석기(노리-Nori) 사용에 대한 설정으로,
설정(settings)의 색인(index) 관련 부분을 모두 모아서 지정한다.
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "nori_user_dict",
"char_filter": ["html_strip"],
"filter": [
"nori_posfilter", "stop_filtering", "lowercase", "stemmer", "nori_readingform", "synonym_filter"
]
}
},
내용에서 HTML 태그는 제거하고(html_strip),
품사로 불용어를 제거하거나(nori_posfilter) 불용어 사전으로 제거하는 (stop_filtering)등의 색인하는 과정을 정의한다.
보다 자세한 것은 인터넷 자료를 참고하고 여기서는 넘어간다.
구조(mappings)는 속성(properties)만 있고, 그 하위에는 저장하는 필드들에 대해서 정의한다.
"bgno": {"type": "long"},
"brdno": {"type": "keyword"},
"brddate": {"type": "date"},
생략 ~~
"brdtitle": {"type": "text","analyzer":"nori_analyzer"},
"brdmemo": {"type": "text","analyzer":"nori_analyzer"},
"brdreply": {
"type": "nested",
"properties": {
"reno": {"type": "text"} ,
"redate": {"type": "text"} ,
"rememo": {"type": "text", "analyzer":"nori_analyzer"} ,
"usernm": {"type": "text"} ,
"userno": {"type": "text"}
}
생략 ~~ 필드 타입(type)이 long, keyword, date 형 등은 값 그대로 색인하는 필드이고,
nori_analyzer로 지정된 필드는 앞서 정의한 nori_analyzer 과정데로 형태소 분석을 하고 색인한다.
댓글(brdreply)과 첨부 파일(brdfiles)은 RDBMS의 부모/자식 관계에 있는 데이터를 저장하기 위한 구조로 nested 형으로 지정한다.
nested형으로 지정된 데이터는 문서내의 문서로 배열처럼 저장된다.
문서내의 문서이기 때문에 속성(properties)키 하위에 reno, rememo등 다시 문서에 대한 필드 정의를 한다.
개인적으로 Solr보다 직관적이고 사용하기 쉬운 것 같다.
데이터를 수집하는 부분은 Solr의 경우 DIH로 개발자는 SQL문만 작성하면 되지만 (Solr의 장점?)
Elasticsearch에서는 Elasticsearch가 제공하는 Java High Level REST Client로 색인을 구현한다.
gu.search.IndexingCtr에 다음과 같은 구조로 작성한다.
| @Scheduled(cron="0 */1 * * * ?") public void indexingFile() { RestHighLevelClient client = createConnection(); 게시글 이전 색인시 마지막 번호 로드 색인할 게시글 리스트 게시글을 Json으로 작성후 색인 - INSERT 마지막 게시글 번호 저장 ------------------ 댓글 이전 색인시 마지막 번호 로드 색인할 댓글 리스트 댓글을 Json으로 작성후 색인 - UPDATE 마지막 댓글 번호 저장 ------------------ 첨부파일 이전 색인시 마지막 번호 로드 색인할 첨부파일 리스트 첨부파일에서 텍스트 추출(Tika) 첨부파일 정보를 Json으로 작성후 색인 - UPDATE 마지막 첨부파일 번호 저장 } |
게시글, 댓글, 첨부파일 모두 동일한 방식으로 작성하였고,
첨부파일은 파일에서 색인할 텍스트를 추출하는 Tika를 사용한다.
셋 모두 이전에 마지막으로 색인한 글 번호 (Pk-Primary Key) 이후의 데이터들을 조회한다.
Solr에서는 날짜(brddat)로 구현했지만, Elasticsearch에서는 글번호로 구현했다.
고유한 값을 가지는 필드면 어떤 것이라도 사용할 수 있다.
마지막 색인 값으로 마지막으로 색인한 이후의 증가된 데이터만 색인하고,
마지막 색인 값이 없는(NULL) 경우는 모든 데이터가 대상이 되어 풀색인을 한다.
SQL문을 그렇게 하도록 다음과 같이 작성하였다.
| <select id="selectBoards4Indexing" resultType="gu.board.BoardVO" parameterType="String"> SELECT BGNO, BRDNO, CU.USERNM, TB.USERNO, BRDTITLE, BRDMEMO , LEFT(BRDDATE, 10) BRDDATE, RIGHT(BRDDATE, 8) BRDTIME FROM TBL_BOARD TB INNER JOIN COM_USER CU ON CU.USERNO=TB.USERNO WHERE TB.BRDDELETEFLAG='N' AND BRDNO > #{brdno} ORDER BY BRDNO LIMIT 20 </select> |
추출한 색인 대상들은 Java의 VO개체에 담겨서 동적 배열(List)형태로 관리되는데,
| List boardlist = (List) boardSvc.selectBoards4Indexing(brdno); List replylist = (List) boardSvc.selectBoardReply4Indexing(lastVO); List filelist = (List) boardSvc.selectBoardFiles4Indexing(lastVO); |
반환 된 개수 만큼 반복하면서 (for), VO에 있는 필드의 값을 Json 형태로(키:값) 저장한다.
게시판은 source로 지정해서 작성했고,
| IndexRequest indexRequest = new IndexRequest(INDEX_NAME) .id(el.getBrdno()) .source("bgno", el.getBgno(), "brdno", brdno, "brdtitle", el.getBrdtitle(), "brdmemo", el.getBrdmemo(), "brdwriter", el.getUsernm(), "userno", el.getUserno(), "brddate", el.getBrddate(), "brdtime", el.getBrdtime() ); |
댓글과 첨부 파일은 Map 구조로 작성했다.
| Map<String, Object> replyMap = new HashMap<String, Object>(); replyMap.put("reno", reno); replyMap.put("redate", el.getRedate()); replyMap.put("rememo", el.getRememo()); replyMap.put("usernm", el.getUsernm()); replyMap.put("userno", el.getUserno()); Map<String, Object> singletonMap = Collections.singletonMap("reply", replyMap); UpdateRequest updateRequest = new UpdateRequest() .index(INDEX_NAME) .id(el.getBrdno()) .script(new Script(ScriptType.INLINE, "painless", 생략~ |
모두 키와 값으로 구성된 Json 방식으로 둘 중 어느 방식을 사용해도 된다.
가장 중요한 처리로 게시글은 IndexRequest로 색인하고(저장하고), 댓글과 첨부 파일은 UpdateRequest로 색인한다.
게시글을 먼저 처리해서 저장하고(Insert)
댓글과 첨부 파일은 해당 게시글을 찾아서 수정하는(Update) 방식으로 구현한다.
더우기 RDBMS의 부모/자식, 1 : n (일대다)의 관계,
즉 하나의 게시물이 여러개의 댓글과 첨부 파일을 가지기 때문에 다음과 같이 다소 복잡한 코드로 저장한다.
|
.script(new Script(ScriptType.INLINE, "painless", "if (ctx._source.brdreply == null) {ctx._source.brdreply=[]} ctx._source.brdreply.add(params.reply)", singletonMap)); |
painless라는 Elasticsearch에서 제공하는 스크립트 언어로
게시물 문서에서 brdreply 라는 필드를 배열( [ ] )로 초기화하고,
생성된 댓글이나 첨부 파일 하나(Json)를 다음과 같이 배열에 추가(add)하는 방식으로 작성한다.
| { "_index": "project9", "_type": "_doc", "_id": "38", "_score": 1, "_source": { "bgno": "3", "brdno": "38", "brdtitle": "거침없이 배우는 Jboss", "brdmemo": "거침없이 배우는 Jboss", "brdwriter": "이종무", "userno": "24", "brddate": "2020-03-01", "brdtime": "17:42:42", "brdreply": [ { "reno": "1", "usernm": "관리자", "redate": "2020-03-08 09:43:27.0", "rememo": "윈도우", "userno": "1" } ] } }, |
이 코드 덕분인지 Solr보다 직관적인 모습으로 색인되어 저장된다 (Solr Nested 참고).
이렇게 작성된 코드는 스프링 스케쥴러를 이용해서 1분마다 실행되게 작성했다.
@Scheduled(cron="0 */1 * * * ?")
실제로 사용할 경우에는 사용자가 없는 새벽 1시에 일괄 색인하는 경우가 많다.
웹 브라우저에서 게시판을 접속해서 게시글을 추가하거나 댓글을 작성하면 잠시 뒤에 검색된다.
검색
검색도 기존 Prohect9 프로젝트에 구현되어 있으며
하나의 Java파일(gu.search.SearchCtr)과 JSP(search.jsp) 파일로 작성하였다.
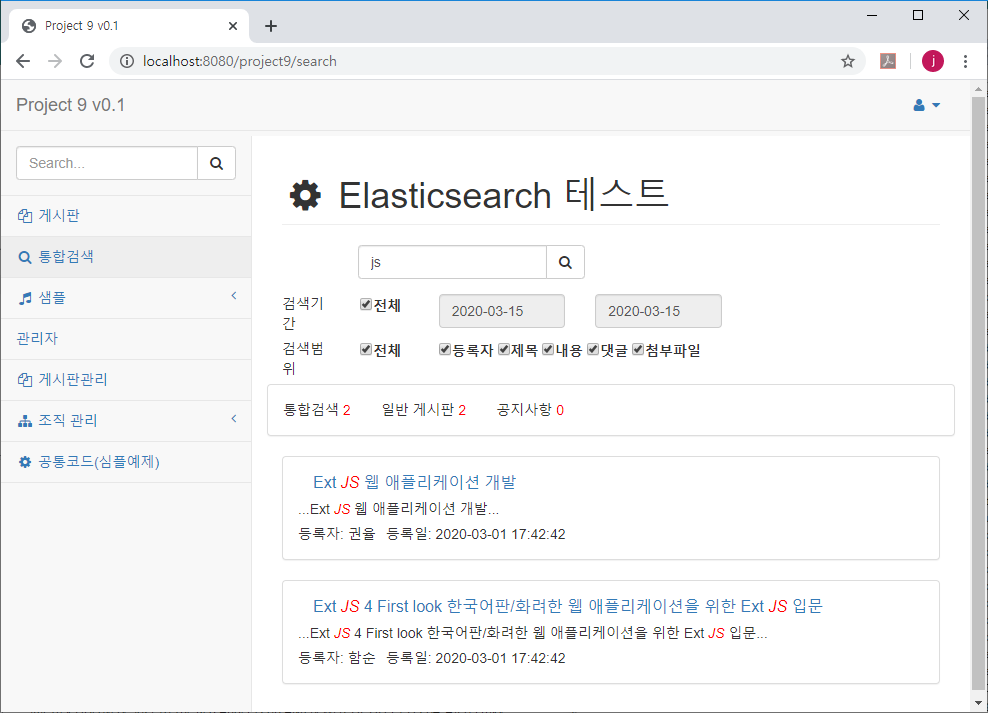
search.jsp 파일은 검색 결과를 Json으로 받아서 적절하게 보여주는 기능을 하고, 여기서 정리하지 않는다.
SearchCtr.java 파일은 High Level REST Client를 기반으로 작성하였고,
검색식을 만드는 부분과 Elasticsearch에 질의하는 부분으로 구분할 수 있다.
반환 된 결과는 Json으로 작성되어 있어서 그데로 jsp로 전달하고 종료한다.
검색식을 만드는 기본 코드는 다음과 같이 makeQuery()함수에서 작성한다.
private BoolQueryBuilder makeQuery (String[] fields, String[] words, FullTextSearchVO searchVO) {
BoolQueryBuilder qb = QueryBuilders.boolQuery();
String searchType = searchVO.getSearchType();
if (searchType!=null & !"".equals(searchType)) {
qb.must(QueryBuilders.termQuery("bgno", searchType));
}
if (!"a".equals(searchVO.getSearchTerm())) { // 기간 검색
qb.must(QueryBuilders.rangeQuery("brddate").from( searchVO.getSearchTerm1()).to( searchVO.getSearchTerm2()) );
}
for( String word : words) { // 검색 키워드
word = word.trim().toLowerCase();
if ("".equals(word)) continue;
BoolQueryBuilder qb1 = QueryBuilders.boolQuery();
for( String fld : fields) { // 입력한 키워드가 지정된 모든 필드에 있는지 조회
if ("brdreply".equals(fld)) { // 댓글은 nested로 저장되어 있어 별도로 작성
qb1.should(QueryBuilders.nestedQuery("brdreply", QueryBuilders.boolQuery().must(QueryBuilders.termQuery("brdreply.rememo", word)), ScoreMode.None));
} else
if ("brdfiles".equals(fld)) { // 첨부 파일은 nested로 저장되어 있어 별도로 작성
qb1.should(QueryBuilders.nestedQuery("brdfiles", QueryBuilders.boolQuery().must(QueryBuilders.termQuery("brdfiles.filememo", word)), ScoreMode.None));
} else {
qb1.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery(fld, word)));
}
}
qb.must(qb1); // 검색 키워드가 여러개일 경우 and로 검색
}
return qb;
}Elasticsearch이 기본적인 검색은 필드:키워드 구조로 Solr와 유사하지만,
다음과 같이 보다 더 Json 구조로 직관적인 구조로 작성한다.
| { "query":{ "match":{ "brdtitle":"js" } } } |
Solr는 필드:키워드가 and, or, ()로 표현되자만,
Elasticsearch은 위와 같은 Json 구조에 must(and), should(or), []로 표현된다.
따라서 위 코드의 마지막 Else문이 기본 검색으로, 이상의 json을 표현한 것이다.
| qb1.should(QueryBuilders.boolQuery().must(QueryBuilders.termQuery(fld, word))); |
댓글(brdreply)과 첨부파일(brdfiles)은 해당 필드에 값이 있으면 게시글이 조회 되어야 하기 때문에 nestedQuery 를 이용해서 따로 작성한다.
|
QueryBuilders.nestedQuery("brdreply", |
사용자가 여러개의 키워드를 입력할 수 있기 때문에 공백 단위로 잘라서 개수 만큼 반복하고
이 키워드들을 조회할 필드들 개수 만큼 반복해서 검색식을 만들기 때문에 두개의 반복문을 실행한다.
| for ( String word : words) { for ( String fld : fields) { |
날짜를 기간으로 검색하기 위해 rangeQuery를 사용하고,
공지사항과 일반 게시판 중 하나를 선택해서 조회할 수 있도록 게시판 종류(bgno)를 지정할 수 있게 하였다.
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.highlighter( makeHighlightField ( searchRange ) ); // 검색 대상 필드에 대해서 하이라이트(댓글, 첨부파일은 제외)
searchSourceBuilder.fetchSource(INCLUDE_FIELDS, null);
searchSourceBuilder.from( (searchVO.getPage()-1) * DISPLAY_COUNT); // 페이징
searchSourceBuilder.size(DISPLAY_COUNT);
searchSourceBuilder.sort(new FieldSortBuilder("_score").order(SortOrder.DESC)); // 정렬
searchSourceBuilder.sort(new FieldSortBuilder("brdno").order(SortOrder.DESC));
TermsAggregationBuilder aggregation = AggregationBuilders.terms("gujc").field("bgno"); // 그룹별(게시판) 개수
searchSourceBuilder.aggregation(aggregation);
searchSourceBuilder.query( makeQuery ( searchRange, searchVO.getSearchKeyword().split(" "), searchVO )); // 검색식 작성
SearchRequest searchRequest = new SearchRequest();
searchRequest.indices(INDEX_NAME);
searchRequest.source(searchSourceBuilder);
RestHighLevelClient client = null;
SearchResponse searchResponse = null;
client = createConnection();
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
이렇게 작성한 검색식은 query로 실행하지만
하이라이팅(highlighter), 페이징(from, size), 정렬(sort)의 설정을 추가해서 실행한다.
특히, 다양한 데이터를 조회하는 통합 검색 기능을 흉내내기 위해
여기서는 공지사항과 일반 게시판의 게시판 종류(bgno) 기능을 구현하였고,
게시판 종류(bgno)별 개수를 확인하기 위해 Elasticsearch에서 제공하는 집계(aggregation) 기능을 이용한다.
|
TermsAggregationBuilder aggregation = AggregationBuilders.terms("gujc").field("bgno"); // 그룹별(게시판) 개수 |
이렇게 실행된 결과는 Json으로 반환되고, 이 값은 그대로 JSP로 전달해서 처리한다.
JavaScript가 Json을 쉽게 사용할 수 있기 때문이지만,
JSP까지 정리하면 검색과 관계없는 코드로 너무 길어질 것 같아서 여기까지 정리한다.
이상의 예제는 게시글/댓글,파일에 대한 색인과 검색에 대한 것으로
글이 수정되거나 삭제 된 경우에 대한 것도 처리가 필요하다.
게시판 프로그램 자체를 수정해야 해서 구현하지 않았다.
이런 부분까지 구현하면 실사용에서도 무난하게 사용할 수 있을 것이다.
'서버 > 검색엔진' 카테고리의 다른 글
| 2. 검색엔진 실전 예제 - Solr 주요 설정과 코드 (2) | 2020.03.15 |
|---|---|
| 3. 검색엔진 실전 예제 - Elasticsearch 설치 (0) | 2020.03.15 |
| 검색 엔진, 챗봇 개발에 유용한 사전 (0) | 2020.02.16 |
| 1. Solr 예제 분석 - 설치 (1) | 2020.01.12 |
| 2. Solr 예제 분석 - 기술제품과 검색식 (3) | 2020.01.12 |