메일 서버를 운영하면, 어떻게 아는지 몰라도 매일 매일 많은 스팸 메일들을 수신하게 된다.
이 스팸 메일들을 차단하기 위해 스팸 서버를 별도로 구축하기도 하지만, 메일 서버에 스팸 필터를 설치하여 구현할 수도 있다.
앞서서 SpamAssassin을 이용하여 스팸 서버를 구축하는 것을 정리하였고
여기에서는 SpamAssassin을 Apache James 메일 서버의 스팸 필터로 사용하는 2 가지 방법을 정리한다.
|
메일 관련 내용들 2. 스팸 메일 서버 구축: Postfix & Apache SpamAssassin 3. 메일 서버와 스팸 필터: Apache James & SpamAssassin |
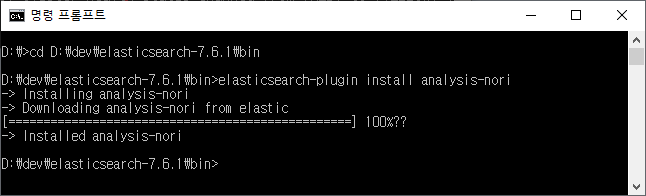
먼저, SpamAssassin을 다음 명령어로 설치한다.
사용하는 리눅스에 따라서 설치하는 명령어만 다를 뿐 나머지는 동일하다 (CentOS를 기준).
CentOS > sudo yum install spamassassin
Ubuntu > sudo apt-get install spamassassin
좀 더 상세한 설치는 스팸 서버 구축에 정리한 인터넷 자료를(url) 참고 하면 된다.
SpamAssassin을 설치하고, SpamAssassin 설정(local.cf) 파일을 다음과 같이 수정한다.
CentOS > vi /etc/mail/spamassassin/local.cf
Ubuntu > vi /etc/spamassassin/local.cf
| required_hits 2 report_safe 0 rewrite_header Subject [SPAM] |
SpamAssassin은 지정되거나 학습된 규칙에 의해서 메일을 평가해서 점수로 환산하고, 지정된 값(required_hits) 이상이면 스팸으로 표시한다.
위 설정외에도 다양한 설정을 할 수 있는데, 설정에 대한 상세한 내용은 이 사이트에 정리된 내용을 참고하면 된다.
기본 값은 5인데, 이렇게 지정되면 테스트하기 어렵기 때문에 2으로 수정한다.
수정내용을 반영하기 위해서 SpamAssassin을 재가동 한다.
> sudo service spamassassin restart
이상으로 SpamAssassin에서 처리할 것은 완료 되었다.
이제부터는 Apache James 에서 Spam 설정을 하고, 메일 테스트를 진행한다.
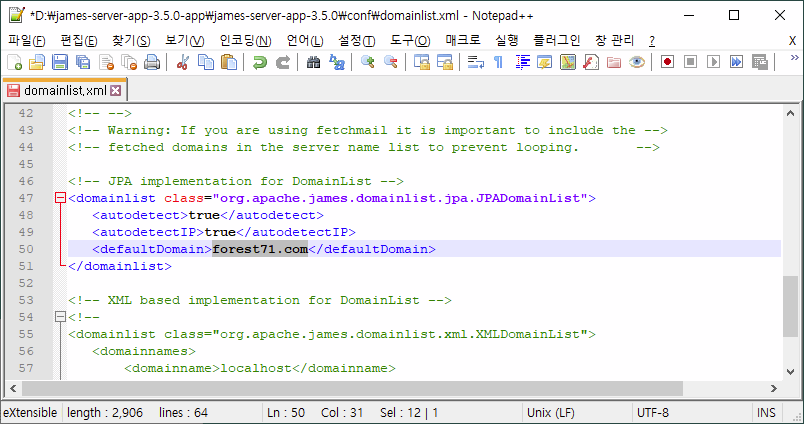
먼저, James를 설치한 폴더 하위의 conf 파일 중 smtpserver.xml파일을 열어서
SpamAssassinHandler를 사용할 수 있도록 주석으로 처리된(<!-- -->) 부분을 삭제한다.
> vi conf/smtpserver.xml
| <!-- <handler class="org.apache.james.smtpserver.fastfail.SpamAssassinHandler"> <spamdHost>127.0.0.1</spamdHost> <spamdPort>783</spamdPort> <spamdRejectionHits>2</spamdRejectionHits> </handler> --> |
SpamAssassin은 지정되거나 학습된 규칙에 의해서 메일을 평가해서 점수로 환산한다.
Apache James가 수신한 메일을 SpamAssassin에 넘기고, SpamAssassin이 평가한 점수를 반환 받아서 spamdRejectionHits 값으로 지정한 값 이상이면 메일을 수신하지 않고 돌려 보낸다.
spamdRejectionHits의 기본 값은 10으로 되어 있는데, 값이 너무 높으면 테스트를 할 수 없기 때문에 2로 수정해서 테스트 한다.
수정한 내용을 반영하기 위해서 Apache James를 제가동 한다.
> sudo bin/james restart
로그를 확인해서 제임스 재가동 완료 여부를 확인한다 (10여초 이상이 걸린다).
> tail -f log/wrapper.log
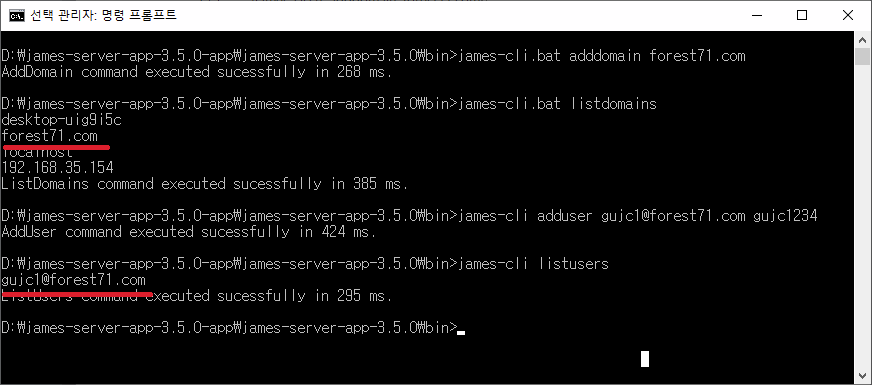
메일을 주고 받기 위해 앞서 생성한 생성한 계정(gujc1)외에 하나 더 생성(gujc2)하거나
생성한 하나의 계정으로 메일을 주고 받도록한다.
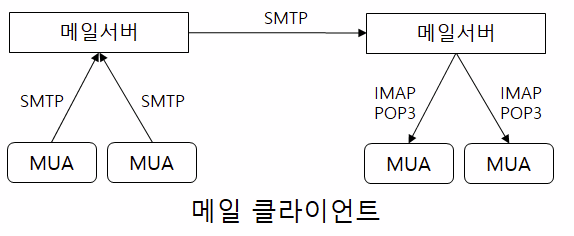
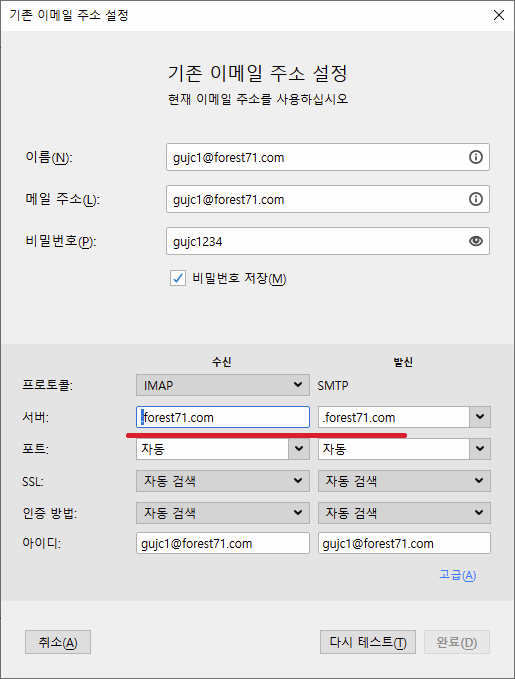
여기서는 썬더버드(Thunderbird)를 사용할 예정인데,
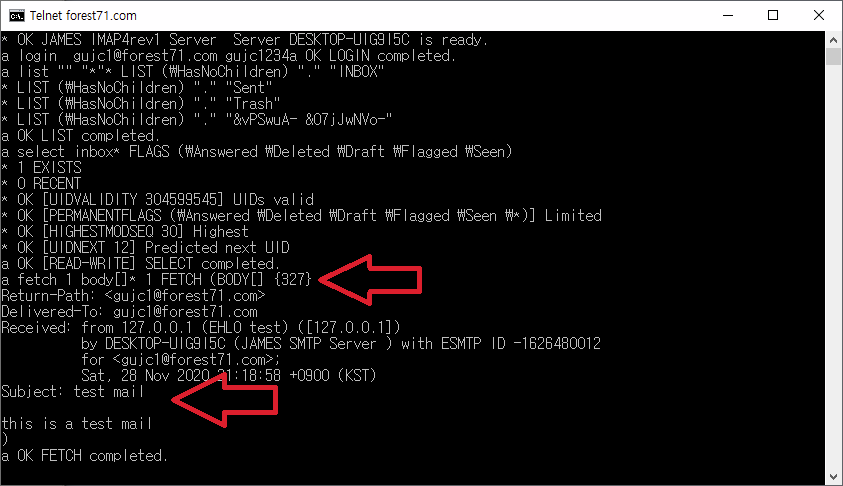
아웃룩등의 MUA을 실행해서 생성한 메일 계정을 등록하고 다음과 같이 메일을 발송한다.
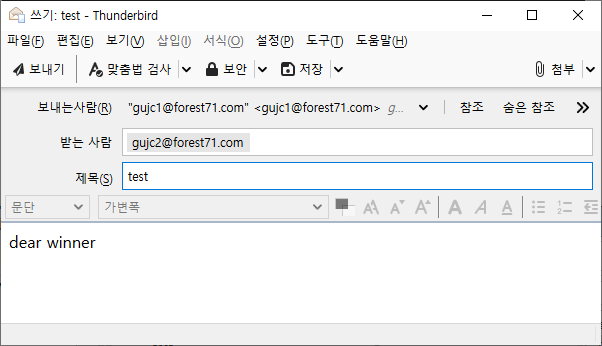
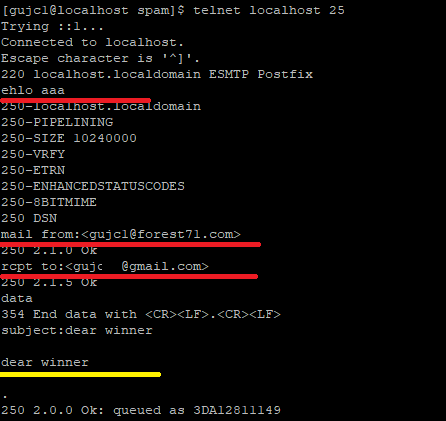
메일 본문에 dear winner를 입력하고 메일을 발송한다.
다음과 같이 오류가 발생하는 것을 확인할 수 있다.

지금 보내려는 메시지는 스팸인 것 같으니, 스팸이 아니라면 관리자에게 연락하라는 메시지가 나타난다.
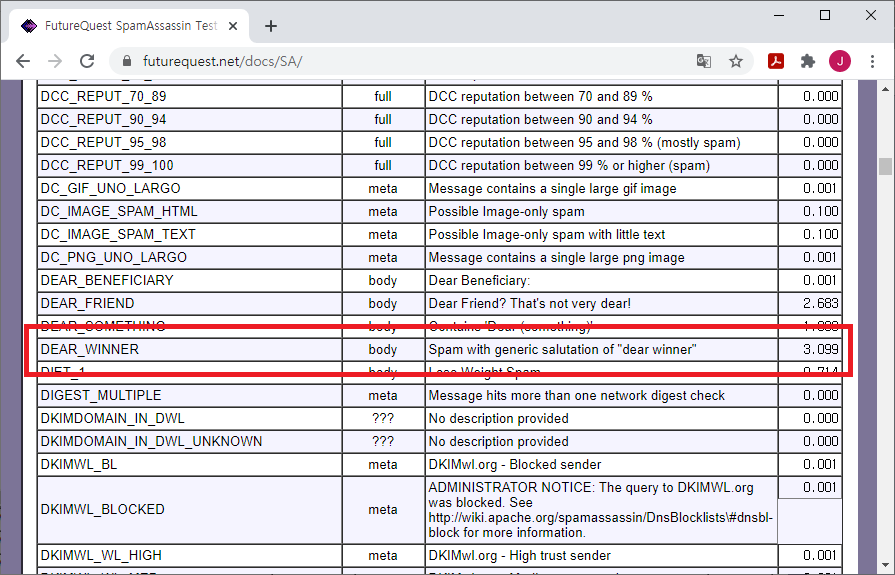
dear winner는 스팸 발송자들이 많이 사용하는 단어로
이 단어가 메일 본문에 있으면 SpamAssassin가 스팸으로 판단해서 Apache James에게 알려주고
Apache James가 위와 같이 수신 거부를 하게 된다.
dear winner 같은 스팸 단어와 관련된 자세한 내용은 스팸 서버 구축에 정리된 내용을 참고하면 된다.
앞서서 smtpserver.xml파일에서 수정했던 SpamAssassin 설정 부분을 다시 주석처리하고
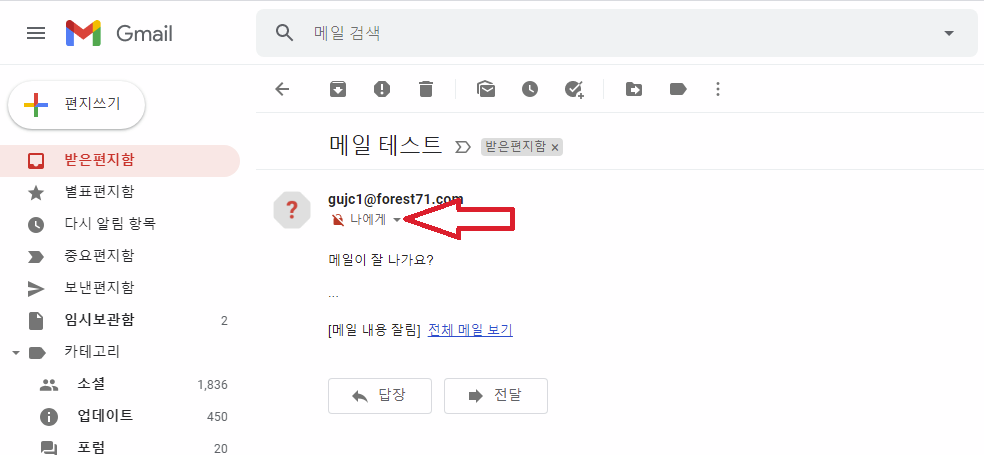
Apache James를 재가동하고 메일을 보내면 다음과 같이 메일이 잘 송신되고 수신되는 것을 볼 수 있다.
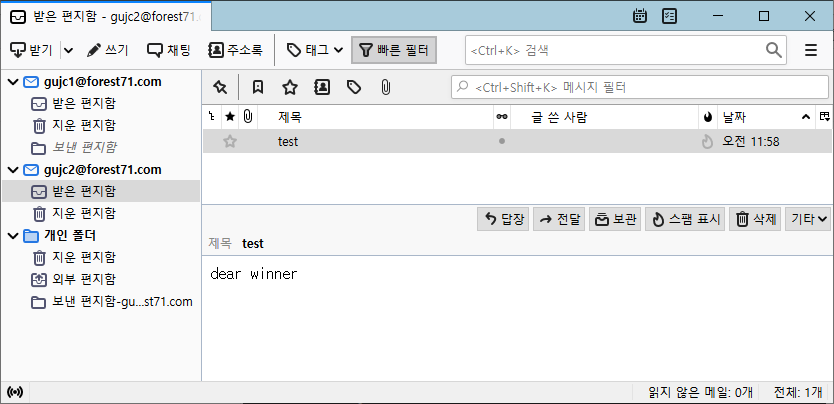
이 방식은 수신된 메일이 확실하게 스팸 메일(spamdRejectionHits 이 10 이상- 테스트는 2)이면 되돌려 보내는 것이다.
하지만 수신한 메일이 스팸인지 애매한 경우도 있다.
spamdRejectionHits에 지정된 값 보다 작지만 (즉, 수신되었지만)
앞서 SpamAssassin에서 지정한 required_hits 값보다 큰 메일은 메일 수신자의 스팸 폴더에 넣어주는게 좋다.
(required_hits의 기본값은 5이지만, 앞서서 테스트를 위해 2로 지정했다.)
대부부의 상용 메일 서버들은 스팸으로 의심되는 메일들은 각 개인의 스팸 폴더에 넣어주고,
개인이 판단하도록 하기 때문에 여기에서도 이 방식을 구현한다.
앞서서 smtpserver.xml파일에서 수정했던 SpamAssassin 설정 부분을 다시 주석처리하거나
spamdRejectionHits 값을 10 이상으로 수정해서 스팸 메일을 반환하지 않도록 한다.
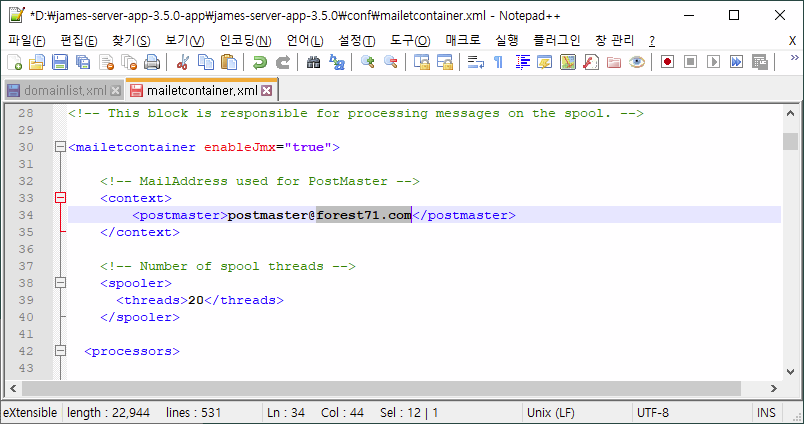
스팸 폴더에 메일을 저장하기 위해, conf 폴더에 있는 mailetcontainer.xml 파일에 다음 설정을 추가한다.
> vi conf/mailetcontainer.xml
| 생략 ~~ <processor state="root" enableJmx="true"> 생략 ~~ <mailet match="SMTPAuthSuccessful" class="ToProcessor"> <processor>transport</processor> </mailet> <mailet match="All" class="SpamAssassin"> <spamdHost>localhost</spamdHost> <spamdPort>783</spamdPort> </mailet> <mailet match="HasHeader=org.apache.james.spamassassin.flag=YES" class="ToProcessor"> <processor>spam</processor> </mailet> |
mailetcontainer.xml는 메일을 처리하는 주요 과정을 설정하는 파일로,
메일을 수신하면 SpamAssassin클래스를 실행해서 스팸 확인을 하도록 추가하였다.
match 문은(Macher) 일종의 if문을 의미하는데,
위 코드에서는 모든 메일(All)은 SpamAssassin에 접속해서 스팸 여부를 확인하는 SpamAssassin클래스를 거치도록 하였다.
SpamAssassin클래스에서는 스팸 여부를 확인후 org.apache.james.spamassassin.flag헤더를 추가하고 YES / NO 값을 지정한다.
다음 match에서는 검사후 org.apache.james.spamassassin.flag헤더의 값이 YES이면
spam처리를 하는 spam프로세스(<processor>spam</processor>)로 이동한다.
| 주의: 인터넷 검색 자료(공식자료?)에서는 HasMailAttributeWithValue=org.apache.james.spamassassin.flag,YES를 사용하도록 되어 있다. HasMailAttributeWithValue는 속성값을 확인하는 것인데, 이유는 모르지만 제대로 작동하지 않는다. 여기에서는 헤더 값을 확인하는 HasHeader를 사용했다. 상세한 설명은 Apache James Macher 문서에 정리되어 있다. |
mailetcontainer.xml 하단에 다음과 같이 spam프로세스를 처리하는 부분이 있다.
| <processor state="spam" enableJmx="true"> <!-- To place the spam messages in the user junk folder, uncomment this matcher/mailet configuration --> <!-- <mailet match="RecipientIsLocal" class="ToRecipientFolder"> <folder>Junk</folder> <consume>false</consume> </mailet> --> <mailet match="All" class="ToRepository"> <repositoryPath>file://var/mail/spam/</repositoryPath> </mailet> </processor> |
스팸으로 확인된 메일은 지정된 경로(repositoryPath)에 저장하도록 되어 있다.
이 Matcher를 삭제하고, 그 위에 주석으로(<!-- -->) 작성된 코드에서 주석을 제거한다.
| <processor state="spam" enableJmx="true"> <!-- To place the spam messages in the user junk folder, uncomment this matcher/mailet configuration --> <mailet match="RecipientIsLocal" class="ToRecipientFolder"> <folder>Junk</folder> <consume>false</consume> </mailet> </processor> |
수신자(Recipient)가 Apache James에 등록된(local) 사용자면 (RecipientIsLocal)
수신자 저장 클래스를(ToRecipientFolder) 실행해서 스팸(Junk) 폴더에 저장하도록 한다.
스팸으로 지정되면, 한 폴더에 모으는 것이 아니고 각 개인의 스팸 폴더에 저장해서 개인이 볼 수 있도록 설정했다.
마지막 설정으로 수신한 스팸을 저장할 개인별 Junk 폴더를(메일함) 생성한다.
james-cli.sh CreateMailbox private 이메일주소 Junk

Apache James를 재가동하고,
선더버드와 같은 MUA에서 다음과 같이 스팸 메일을 발송한다.
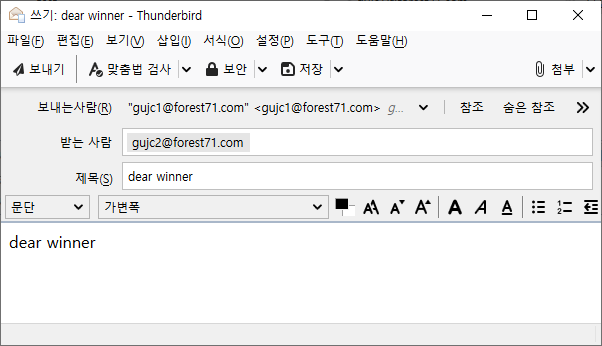
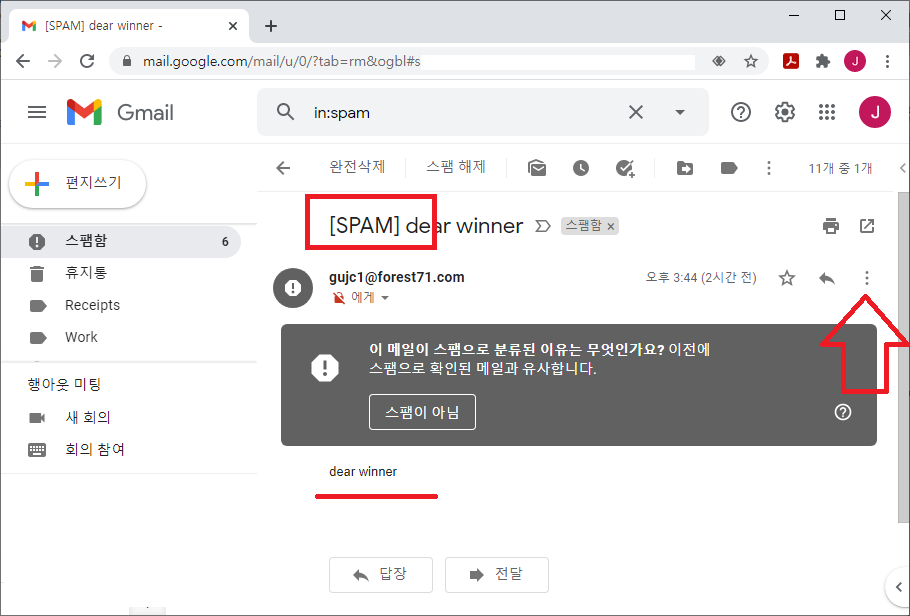
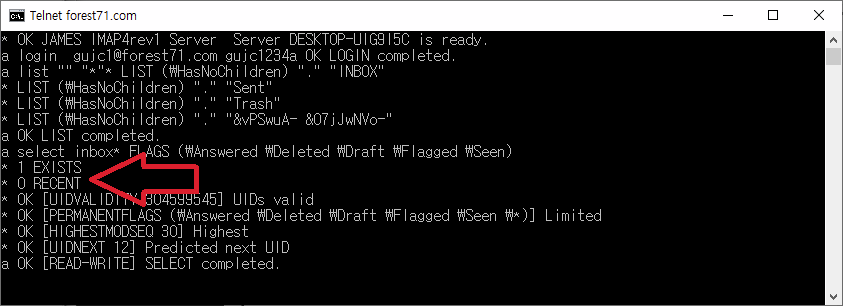
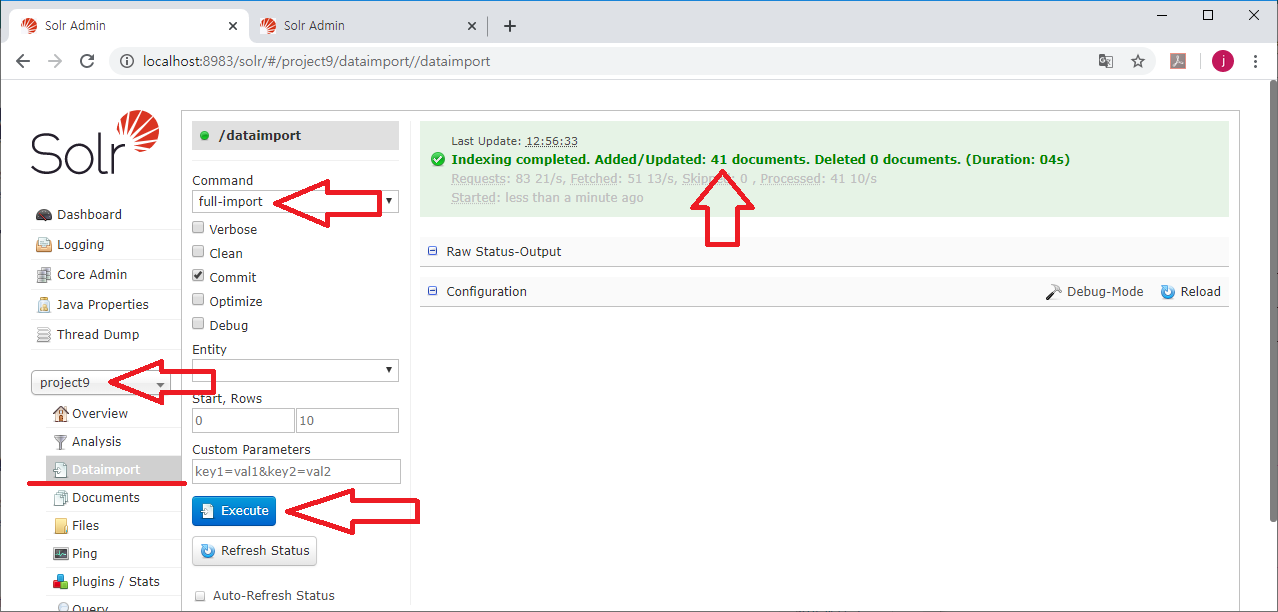
그림과 같이 [스팸 편지함]에 메일이 제대로 저장 되는 것을 볼 수 있다.
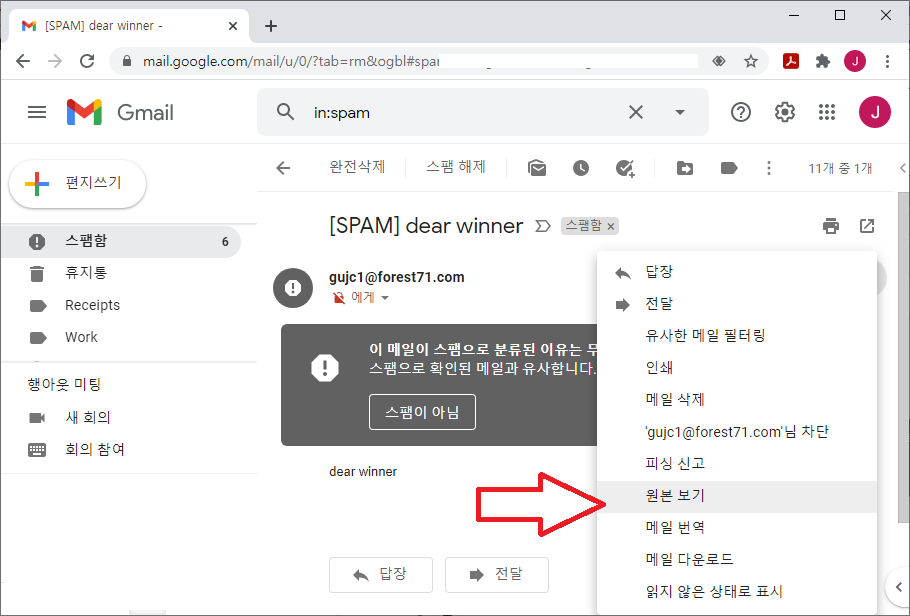
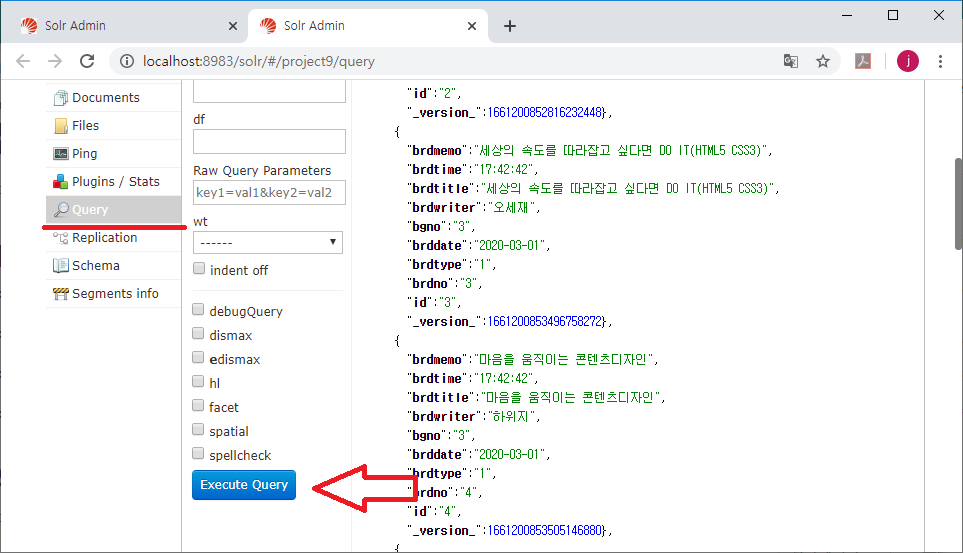
수신한 메일을 선택하고 그림 우측 중앙에 있는 [기타]를 선택해서, [소스보기]를 실행한다.
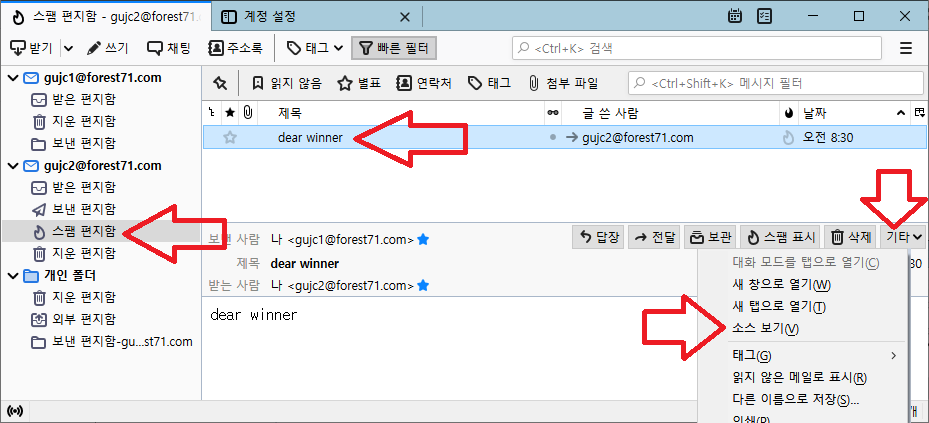
다음과 같이 수신한 메일의 EML 원문 내용을 볼 수 있는데, 메일 헤더에 스팸 메일로 표시되어 있다.
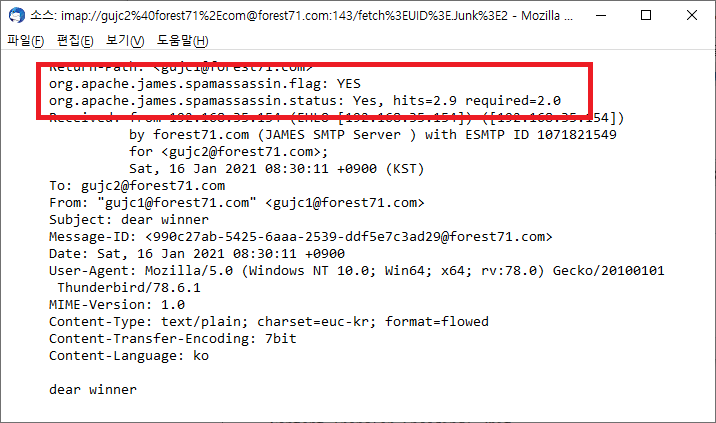
org.apache.james.spamassassin.flag가 YES이고, 스팸 점수가 2.9점으로 표시되었다.
위 그림과 같이 [스팸 편지함]이 보이지 않는 경우,
썬더보드의 경우 해당 메일 계정을 선택하고 마우스 오른쪽 버튼을 눌러서 [설정] 메뉴를 실행한다.
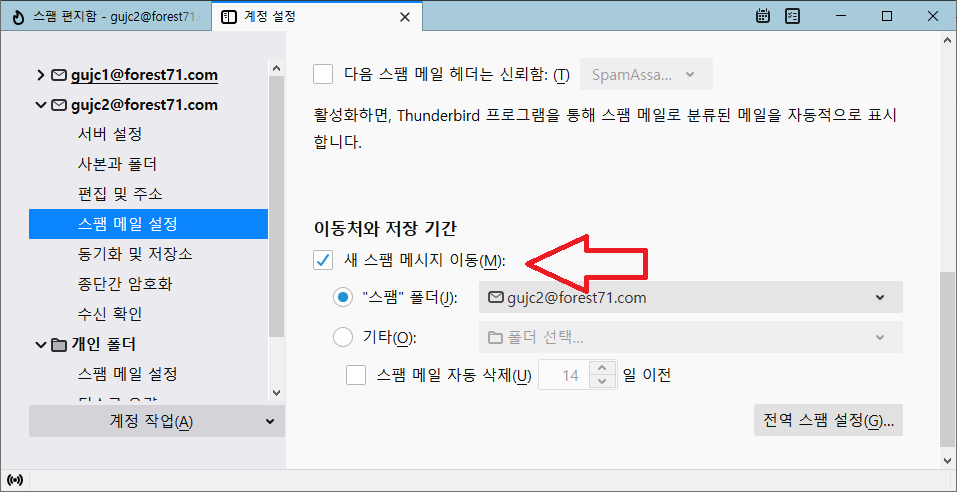
계정 설정 화면 하단에 있는 [새 스팸 메시지 이동]을 선택하고, 편지함 탭을 선택하면 [스팸 편지함]을 볼 수 있다.
이상으로 SpamAssassin을 Apache James 의 스팸 필터로 사용하는 방법을 정리하였다.
SpamAssassin을 스팸 서버로 사용하는 방법도 정리하였는데,
SpamAssassin을 스팸 서버로 사용하는 경우,
스팸 메일이면 메일헤더에 X-Spam-Flag가 추가되고 YES값이 추가된다(참고).
앞서 mailetcontainer.xml 에서 설정한 스팸 필터 연동 부분을 삭제하고 (<mailet match="All" class="SpamAssassin">)
스팸 여부를 확인하는 HasHeader=org.apache.james.spamassassin.flag=YES 대신에
HasHeader=X-Spam-Flag=YES을 지정하면 스팸서버에서 판단한 스팸 메일을 각 개인의 스팸 메일함(Junk)에 저장할 수 있다.
덧붙이는 글
한글 스팸 메일들을 SpamAssassin으로 학습시켜서 스팸 메일을 테스트하는 내용에 대해서 공유할 계획입니다.
자신의 메일 함에 있는, 또는 회사 스팸 서버에 있는 스팸 메일들을 공유해주시면 감사하겠습니다.
net_forest@hanmail.net 으로 보내주세요.
'서버 > 메일' 카테고리의 다른 글
| 스팸 메일 서버 구축 - SpamAssassin & Postfix (0) | 2021.01.09 |
|---|---|
| 1. Apache James 메일 서버 - 설치 (1) | 2020.12.06 |
| 2. Apache James 메일 서버 - 설정 (0) | 2020.12.06 |
| 3. Apache James 메일 서버 - 메일 클라이언트 (3) | 2020.12.06 |
| 4. Apache James 메일 서버 - Text와 JPA(MariaDB등) (0) | 2020.12.06 |