검색 서버를 구축 하려면 필요한 사항이 많지만, 가장 중요한 부분은 색인(Indexing)과 검색(Search)이다.
Solr에서 색인은 DIH (Data Import Handler)로 처리하고
검색식을 Solr 검색엔진에 전송하고 결과를 받아서 보여주는 Java(SolrJ) 부분으로 나누어 구현하였다.
DIH에 대한 사항과 SolrJ 사용법은 각각 이전에 정리하였고
구현 방법을 모두 여기에 정리 할 수 없기 때문에, 색인과 검색에 관련된 몇 가지 주요한 사항만 정리한다.
주의: 용어나 옵션에 대한 상세한 설명을 정리하지 않기 때문에 Solr를 잘 모른다면 다음 내용이 어려울 수 있다.
|
1. Solr 설치 |
정리할 주요 내용은 다음 그림과 같다.
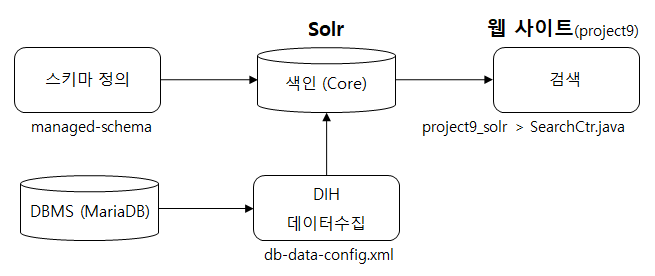
색인
색인 작업은 Solr 검색 서버가 처리하는 것이고,
개발자가 구현하는 것은 Solr가 색인 할 수 있도록 데이터를 수집하는 작업을 의미한다.
데이터 수집 작업은 수집한 데이터를 저장하는 공간에 대한 정의와 데이터를 수집하는 방법에 대한 정의로 구분된다.
앞서서 코어(project9)를 생성하고, 설정에([solr설치경로]\server\solr\project9\conf) 몇 가지 파일을 복사했다.
이 복사한 파일 중 managed-schema 파일은 다음과 같이 코어에 저장한 데이터 구조를 지정하는 파일이다.
<field name="brdtype" type="string" indexed="true" stored="true"/>
<field name="bgno" type="string" indexed="true" stored="true"/>
<field name="brdno" type="string" indexed="true" stored="true"/>
<field name="brdwriter" type="string" indexed="true" stored="true"/>
<field name="brdtitle" type="text_ko" indexed="true" stored="true"/>
<field name="brdmemo" type="text_ko" indexed="true" stored="true"/>
<field name="brddate" type="string" indexed="true" stored="true"/>
<field name="brdtime" type="string" indexed="true" stored="true"/>
<field name="reno" type="string" indexed="true" stored="true" multiValued="false" required="false" />
<field name="rememo" type="string" indexed="true" stored="true" multiValued="false" required="false" />
<field name="fileno" type="string" indexed="true" stored="true" multiValued="false" required="false" />
<field name="filename" type="string" indexed="true" stored="true" multiValued="false" required="false" />
<field name="filememo" type="text_ko" indexed="true" stored="true" multiValued="false" required="false" />게시판의 내용(brd*)과 댓글(reno, rememo), 첨부파일(file*)에 대한 정보를 저장한다.
검색엔진은 RDBMS와 다르게 데이터를 정규화해서 저장하지 않고, 위 코드와 같이 하나의 문서로 모든 내용을 저장한다.
데이터 타입(type)은 여러가지가 있지만
여기서는 형태소 분석기로 분석해서 색인할 데이터는 text_ko라는 사용자 정의 타입으로 지정하고,
그대로 색인할 데이터는 string으로 지정한다.
사용자 정의 타입인 text_ko는 managed-schema 파일 하단에 다음과 같이 정의하였다.
<fieldType name="text_ko" class="solr.TextField" >
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ClassicFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" queryMode="false"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false" />
<filter class="org.apache.lucene.analysis.ko.WordSegmentFilterFactory" hasOrijin="true"/>
<!--filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory"/-->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ko.KoreanTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ClassicFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.KoreanFilterFactory" hasOrigin="true" hasCNoun="true" bigrammable="false" queryMode="false"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false" />
<filter class="org.apache.lucene.analysis.ko.WordSegmentFilterFactory" hasOrijin="true"/>
<filter class="org.apache.lucene.analysis.ko.HanjaMappingFilterFactory"/>
<filter class="org.apache.lucene.analysis.ko.PunctuationDelimitFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
</analyzer>
</fieldType>위 코드는 한글 형태소 분석기인 아리랑을 사용하기 위해 필요한 설정으로 상세한 설명은 인터넷에서 찾아보면 된다.
저장한 공간을 지정한 뒤에는 db-data-config.xml 파일에서 다음과 같이 수집할 데이터를 지정한다.
| <dataSource driver="org.mariadb.jdbc.Driver" url="" user="" password="" readOnly="True"/> <dataSource name="file" type="BinFileDataSource" basePath="d:\workspace\fileupload\" /> <document> <entity name="board" rootEntity="true" query="SELECT "> <field column="brdno" name="id" /> 필드들~~ <entity name="reply" child="true" pk="reno" query="SELECT"> <field column="reno" name="reno" /> <field column="rememo" name="rememo" /> </entity> <entity name="boardFileList" child="true" pk="fileno" query="SELECT"> <field column="fileno" name="fileno" /> <field column="filename" name="filename" /> <entity name="boardFile" processor="TikaEntityProcessor"> <field column="text" name="filememo" /> </entity> </entity> </entity> </document> |
데이터 수집은 SQL문으로 작성하고, DIH 예제 정리를 참고하면 된다.
단순한 구조는 DIH 예제에 정리한 것과 같이 데이터를 가지고 오는 SQL만 초기 전체 데이터와 증가된 데이터에 대해서 작성한다.
여기서 사용된 구조는 조금 복잡한데,
게시판 글이(board) 부모이고, 댓글(reply)과 첨부파일이(boardFileList) 자식인 구조로 작성되었다.
위 XML 코드를 자세히 보면 게시판(board) entity 안에 댓글(reply)과 첨부파일(boardFileList) entity 가 포함되어 있고,
게시판(board) entity는 root로, 댓글(reply)과 첨부파일(boardFileList) entity는 child로 설정한다.
이것을 nested documents라고 한다.
데이터가 직관적으로 저장되지 않아서 개인적으로 Solr가 Elasticsearch보다 조금 부족한 부분이라고 생각하는데,
다음 그림과 같이 자식 데이터인 댓글이 부모와 따로 저장되어 있다.
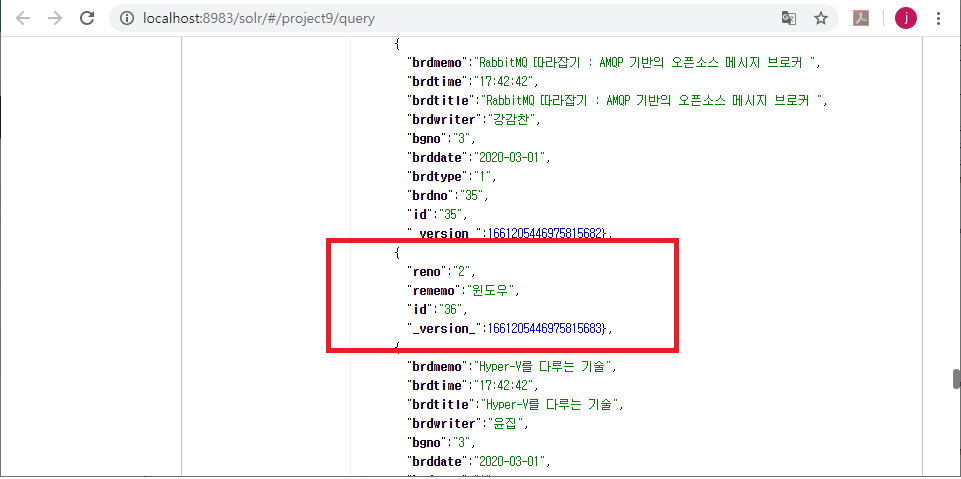
Elasticsearch에서는 자식 데이터가 배열형처럼 처리되어 부모 글과 같이 조회된다.
주의: Solr에서 자식 문서(nested) 처리를 찾기 위해 제법 많은 시간을 허비했지만 찾지 못 한 것 일 수 있음.
마지막으로 첨부 파일은 Tika(TikaEntityProcessor)를 사용해서 텍스트로 변환해서 색인한다.
Tika로 추출된 텍스트(text)는 filememo라는 이름으로 Solr에 색인된다.
검색
검색은 기존 Prohect9 프로젝트에 구현되어 있으며
하나의 Java파일(gu.search.SearchCtr)과 Jsp(search.jsp) 파일로 작성하였다.
search.jsp 파일은 검색 결과를 Json으로 받아서 적절하게 보여주는 기능을 하고, 여기서 정리하지 않는다.
SearchCtr.java 파일은 SolrJ를 기반으로 작성하였고,
검색식을 만드는 부분, SolrJ를 이용하여 Solr에 질의하는 부분, Solr에서 반환 받은 결과를 정리해서 Json으로 작성하는 부분으로 나눌 수 있다.
검색식을 만드는 기본 코드는 다음과 같고
사용자가 입력한 키워드와 검색 필드에 맞추어 Solr(Lucene) 검색식을 생성한다.
Solr(Lucene) 검색식은 기존 자료를 참고하고, 기본적으로 [필드명 : 키워드] 형태로 작성한다.
예를 들어 글 제목에서 JS 란 단어를 찾는 경우 brdsubject:JS가 된다.
private String makeQuery(String keyword, String[] fields) {
String queryStr = "";
for (int i=0; i<fields.length; i++) {
if (queryStr.length()>0) queryStr += " OR ";
if ("brdfiles".equals(fields[i]))
queryStr += " {!parent which=\"brdtype:1\"}filememo:" + keyword;
else
if ("brdreply".equals(fields[i]))
queryStr += " {!parent which=\"brdtype:1\"}rememo:" + keyword;
else queryStr += " " + fields[i] + ":" + keyword;
}
return queryStr;
}makeQuery()함수에서는 작성자(brdwriter), 글 제목(brdsubject), 글 내용(brdmemo) 등의 여러 필드(fields)가 searchRange 변수에 콤마(,)로 묶여서 넘어오기 때문에 콤마로 나누어서(split) 개수만큼 반복한다.
여러개의 필드에서 해당 키워드를 찾기 때문에 OR로 연결한다.
즉, 작성자(brdwriter)에 키워드가 있거나(OR) 글 제목(brdsubject)에 키워드가 있는(OR ...) 문서를 찾는 것이 된다.
|
중요: 기본 검색식 brdsubject:JS는 위 코드에서 마지막 else 문에 있는 코드이다. queryStr += " " + fields[i] + ":" + keyword; 앞서 사용한 if 문들은 nested 처리, 즉, 하나의 게시글에 대한 댓글, 첨부 파일 같은 자식글 검색을 위한 코드로 댓글, 첨부 파일 같은 자식글에서 검색이 되더라도 부모글이 조회되어야 하기 때문에 다음과 같이 별도의 코드를 사용한다. {!parent which="brdtype:1"}rememo:키워드 댓글(rememo)에 키워드가 검색되더라도 글종류(brdtype)가 1인 데이터를 조회하는 것으로 글 종류는 게시물 색인시 1로 저장하도록 작성해 두었다. |
이렇게 작성 한 makeQuery()함수를 호출하는 검색식의 메인 부분은 다음 코드이다.
String searchKeyword = searchVO.getSearchKeyword();
String[] fields = searchVO.getSearchRange().split(","); // 검색 대상 필드 - 작성자, 제목, 내용 등
String[] words = searchKeyword.split(" ");
String queryStr = "";
for (int i=0; i<words.length; i++) {
queryStr += makeQuery(words[i], fields);
}
String searchType = searchVO.getSearchType();
if (searchType!=null & !"".equals(searchType)) {
queryStr = "(" + queryStr + ") AND bgno:" + searchType;
}
if (!"a".equals(searchVO.getSearchTerm())) { // 기간 검색
queryStr = "(" + queryStr + ") AND brddate:[" + searchVO.getSearchTerm1() + " TO " + searchVO.getSearchTerm2() + "]";
}사용자가 입력하는 키워드(searchKeyword)는 공백으로 구분되어 여러 개가 입력될 수 있기 때문에 searchKeyword.split(" ")로 배열을 생성해서, 개수 만큼(words) Solr 검색식을 만든다(makeQuery).
여러 개의 키워드를 입력한 경우도 OR 연산으로 처리하였다.
한 필드에 A 키워드가 있거나 B 키워드가 있으면 조회하도록 한 것이다.
개발하는 조건에 따라 AND로 구현 할 수 있다.
사용자가 입력한 키워드(searchKeyword)와 검색할 필드(searchRange)를 이용해 기본 검색식을 생성하고
날짜(searchTerm)에 대한 조건을 지정할 수도 있고
통합 검색을 흉내내기 위해 게시판 종류(searchType)를 지정할 수 있다.
다만, 기본식은 OR로 연결했지만 날짜와 게시판 종류는 AND로 조회한다.
예를 들면, 게시판 종류가 공지사항이고(AND) 날짜는 3월 1일부터 3월 14일까지의 데이터 중에서(AND)
글제목에 해당 키워드가 있거나 글내용에 해당 키워드가 있는 문서를 조회하기 때문이다.
다음 부분은 검색식을 Solr로 보내는 SolrJ 코드이다.
SolrQuery solrQuery = new SolrQuery();
solrQuery.setQuery(queryStr);
solrQuery.setFields("");
solrQuery.addSort("id", ORDER.desc); // 정렬
solrQuery.setStart( (searchVO.getPage()-1) * DISPLAY_COUNT); // 페이징
solrQuery.setRows(DISPLAY_COUNT);
solrQuery.setFacet(true); // 합계
solrQuery.addFacetField("bgno");
solrQuery.setParam("hl.fl", "brdwriter, brdtitle, brdmemo"); // 하이라이팅
solrQuery.setHighlight(true).setHighlightSnippets(1);
logger.info(solrQuery.toString());
// 실제 조회
QueryResponse queryResponse = null;
SolrClient solrClient = new HttpSolrClient.Builder("http://localhost:8983/solr/project9").build();
try {
queryResponse = solrClient.query(solrQuery);
solrClient.close();
logger.info(queryResponse.toString());
} catch (SolrServerException | IOException e) {
logger.error("solrQuery error");
}정렬, 페이징 처리, 하이라이팅할 필드 등을 지정하고 개수를 집계(facet)할 필드를 지정한다.
facet는 통합 검색 기능을 위한 것으로 게시판 종류(bgno)별로 총 개수를 반환한다.
Solr 서버에 접속하고(SolrClient), 작성한 검색식을(solrQuery) 전송한다(질의한다-query).
실행 결과는 queryResponse에 Json(아닌 부분도 있다.) 형태로 반환된다.
마지막 부분은 검색 결과를 정리해서 Json 형태로 만드는 코드이다.
HashMap<String, Long> facetMap = new HashMap<String, Long>();
List<FacetField> ffList = queryResponse.getFacetFields();
for(FacetField ff : ffList){
List<Count> counts = ff.getValues();
for(Count c : counts){
facetMap.put(c.getName(), c.getCount());
}
}
//Map<String, Map<String, List<String>>> highlights = rsp1.getHighlighting();
HashMap<String, Object> resultMap = new HashMap<String, Object>();
resultMap.put("total", queryResponse.getResults().getNumFound());
resultMap.put("docs", JSONUtil.toJSON(queryResponse.getResults()).toString()) ;
resultMap.put("facet", facetMap) ;
resultMap.put("highlighting", queryResponse.getHighlighting()) ;반환된 queryResponse가 완전한 Json이면 처리 할 것이 없어서 그대로 JSP로 전달하면 좋은데,
아쉽게 조금 부족해서 조금의 처리를 해야 한다.
위 코드의 아래 부분에 있는 resultMap이 반환을 위한 JSon 작성부분으로
total은 검색된 전체 데이터 개수로 numFound 값으로 Solr에서 반환된다.
docs는 검색된 문서들로 5개씩(DISPLAY_COUNT) 반환되는데, getResults()함수로 가져오고 기본적으로 Json이지만 쓸데 없는 코드가 있어서 JSONUtil.toJSON() 함수로 변환해서 사용한다.
facet는 게시판 종류별 개수로 어쩡쩡한 구조로 반환되기 때문에 위 코드 앞부분에서 조금 복잡한 변환 작업을 한다 (facetMap 변수 부분 참조).
highlighting는 Json으로 반환되기 때문에 그대로 전달한다.
다른 인터넷 자료에서는 반환 결과를 VO 개체에 넣는 등 복잡한 처리를 하지만,
JSP에서 Javascript로 쉽게 Json을 사용 할수 있기 때문에 여기서는 반환 데이터를 Json으로 그냥 전송한다.
JSP까지 정리하면 검색과 관계없는 코드로 너무 길어질 것 같아서 여기까지 정리한다.
이상의 예제는 게시글/댓글,파일에 대한 색인과 검색에 대한 것으로
글이 수정되거나 삭제 된 경우에 대한 것도 처리가 필요하다.
일부 구현하였지만 게시판 프로그램 자체를 수정해야 해서 모두 구현하지 않았다.
이런 부분까지 구현하면 실사용에서도 무난하게 사용할 수 있을 것이다.
'서버 > 검색엔진' 카테고리의 다른 글
| 1. 검색엔진 실전 예제 - Solr 설치 (6) | 2020.03.15 |
|---|---|
| 3. 검색엔진 실전 예제 - Elasticsearch 설치 (0) | 2020.03.15 |
| 4. 검색엔진 실전 예제 - Elasticsearch 주요 설정과 코드 (2) | 2020.03.15 |
| 검색 엔진, 챗봇 개발에 유용한 사전 (0) | 2020.02.16 |
| 1. Solr 예제 분석 - 설치 (1) | 2020.01.12 |