Solr 예제를 설치해서 검색하는 방법에 대해서 정의했고,
이번에는 검색을 위해 데이터를 저장하는 방법 중 구조(Schema)를 구성하는 것에 대해서 정리한다.
Solr 예제에서 영화 정보(films)를 이용하여 구조에 대해서 설명하기 때문에, 여기에서도 영화 정보를 이용하여 정리한다.
- 설치
- 기술제품과 검색식
- 스키마(Schema)
- DIH (Data Import Handler)
데이터를 저장하기 위해서는 저장하는 장소, 즉 스키마(Schema)에 대해서 정의해야 한다.
대부분의 데이터는 다음 엑셀 그림처럼 name, directed_by, genre, type, id, initial_release_date 같은 컬럼이 있고, 각각의 데이터가 행으로 저장된다.
각각의 컬럼이 어떤 데이터를 가지는 지를 정의하는 것이 스키마로 데이터 베이스(DBMS)의 용어와 동일한 의미로 사용된다.

그림을 보면 배포일자(initial_release_date)는 년월일의 년도 형 데이터 구조를 가지고 있다.
이 외의 모든 컬럼은 일반 (텍스트, 문자열) 형 데이터 구조를 가지고 있다.
숫자가 있었다면 숫자형 데이터를 가지게 된다.
이렇게 구조를 미리 지정해서 저장하는데, Solr에서는 이 스키마를 미리 정의하지 않고도 사용할 수 있다.
Elasticsearch도 동일한데, 이것을 Schemaless라고 한다.
하지만, 가급적 정의해서 사용하는 것이 좋고, 그 이유를 Solr 예제에서 제공하고 있다.
Solr를 실행하고(solr star), 다음 명령어로 films 코어를 생성한다.
bin/solr create -c films <- Linux, Mac
bin\solr delete -c films <- Windows
예제 폴더(example)에는 앞서 정리한 기술제품(techproducts)외에도 영화 정보(films) 예제 파일이 있다.
이 파일의 내용을 생성한 films 코어에 저장한다.
다음 명령어로 생성한 films 코어에 데이터를 저장한다.
bin/post -c films example/films/films.json <- Linux, Mac
java -jar -Dc=films -Dauto example\exampledocs\post.jar example\films\*.json <- Windows
영화 정보(films) 폴더에는 films.csv, films.json, films.xml 3개의 파일이 있다.
모두 동일한 영화 정보 데이터를 가지고 있고, 이 중에서 json 파일의 내용을 films 코어에 저장하는 명령어이다.

films 코어를 생성하고, 데이터를 저장하면 위 그림과 같이 오류가 발생한다.
그리고, Solr 관리자 화면에서 데이터를 조회(Query)하면, 5개의 데이터가 저장되어 있다.
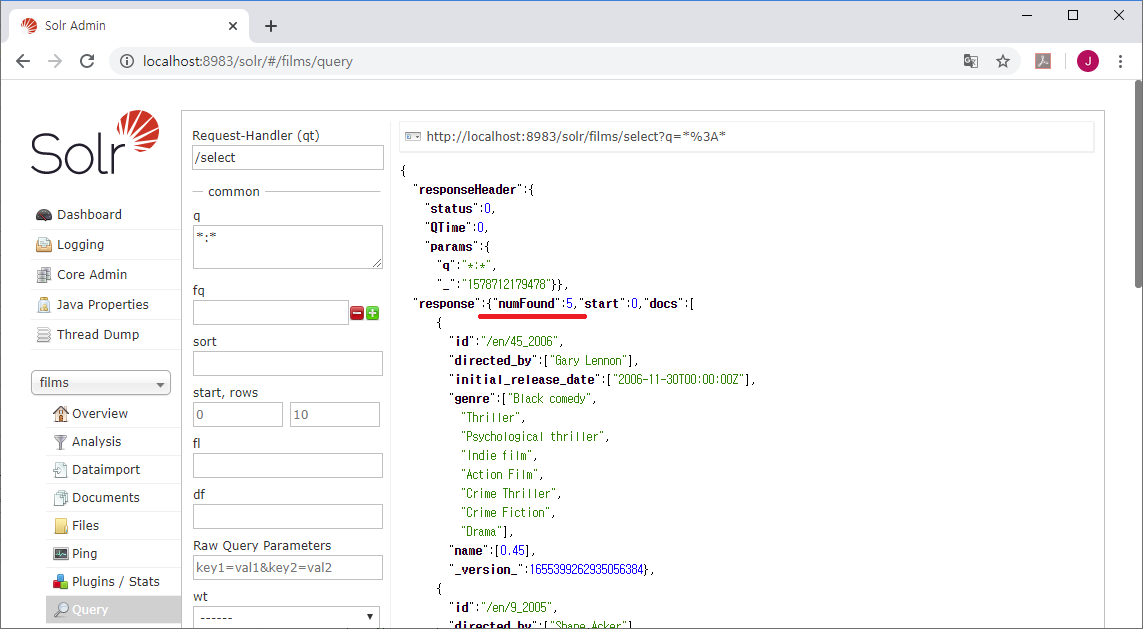
화면을 스크롤 해서 이름(name) 필드의 값을 보면, 모두 실수형이고 배열 ([])이다.
| { "id":"/en/45_2006", ~~ 생략 "name":[0.45], { "id":"/en/9_2005", ~~ 생략 "name":[9.0], { "id":"/en/69_2004", ~~ 생략 "name":[69.0], { "id":"/en/300_2007", ~~ 생략 "name":[300.0], "_version_":1655399262942396417}, { "id":"/en/2046_2004", ~~ 생략 "name":[2046.0], "_version_":1655399262943444992}] } |
Solr 관리자 화면의 스키마(Schema) 화면은 선택된 코어의 필드 구조를 관리 하는 페이지로,
name 필드를 선택하면 type이 pdoubles(실수) 로 생성되어 있다.
(이 화면에서 데이터가 저장되면서 자동으로 생성된 모든 필드들을 볼 수 있다.)

영화 예제 폴더 중에서 csv 파일을 엑셀로 열면, name (A)컬럼의 앞에 있는 5개 데이터가 숫자이다.
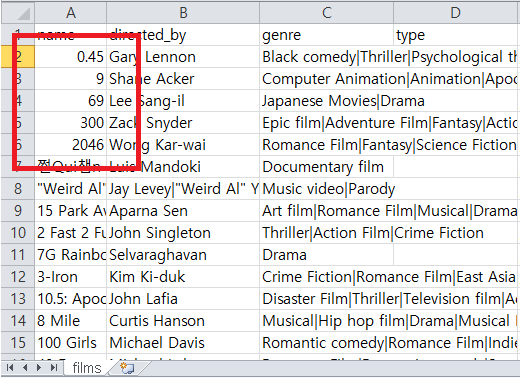
그리고, 6번째 데이터부터 약 1000개의 데이터는 문자이다.
Solr (실재로는 Lucene)에서는 첫 데이터로 컬럼의 구조를 정의하는데,
위와 같이 첫 데이터가 숫자면 컬럼은 숫자(실수)로 정의한다.
즉, 앞서의 데이터 저장시 발생한 오류는 숫자 컬럼에 문자가 입력되어 발생한 오류이다.
name 필드를 삭제하고 새로 생성해서, 이 오류를 해결한다.
Schema 페이지(앞서의 이미지)에서 name 필드를 선택하면 활성화 되는 하단의 [delete field] 버튼을 클릭해서 name 필드를 삭제한다.
그리고, 상단의 [Add Field] 버튼을 클릭하여 name 필드를 다시 생성한다.

그림과 같이 생성할 필드명 name을 입력하고, field type에는 문자열(text_general)을 지정하고 필드를 생성한다 (Add Field).

name 필드가 생성된 것을 확인하고, 앞서 실행했던 데이터 저장을 다시 실행하면(post),
그림과 같이 오류 없이 실행되는 것을 확인 할 수 있다.

Solr 관리자 페이지 Query 에서 데이터를 조회하면, 1100개의 데이터가 저장되어 있다.

Solr나 Elasticsearch에서는 이 스키마를 미리 정의하지 않고도 사용할 수 있지만(Schemaless)
이와 같이 데이터의 구조를 제대로 고려하지 않고 사용하면 문제가 발생하기 때문에 스키마를 정의해서 사용하는 것이 좋다.
이 문제 외에도 긴 문장의 경우에는 형태소 분석 등을 하게 된다.
이런 필드와 그냥 저장하는 필드 등을 미리 정의해야 해서 스키마를 미리 정의해서 사용하는 것이 좋다.
|
또다른 필드 추가 방법 Solr 관리자 화면에서 필드를 지우거나 생성해도 되고, 다음과 같이 RESTful로 처리해도 된다. Linux: curl -X POST -H 'Content-type:application/json' --data-binary '{"delete-field" : { "name":"name" }}' http://localhost:8983/solr/films/schema curl 사용시 리눅스는 홑따옴표(')를 사용하고, 윈도우는 쌍따옴표(")를 사용하는 차이가 있다 윈도우는 쌍따옴표(")를 사용하기 때문에 Json 키/값 표현에 사용되는 쌍따옴표(")는 \"로 표현해야 한다. 필드를 삭제(delete-field) 할 때에는 삭제할 필드명(name)을 name으로 지정한다.
Linux: curl -X POST -H 'Content-type:application/json' --data-binary '{"add-field": {"name":"name", "type":"text_general", "multiValued":false, "stored":true}}' http://localhost:8983/solr/films/schema 필드를 추가(add-field) 할 때에는 필드명(name), 필드 타입(type), 다중값 여부(multiValued, 배열), 저장여부(stored)등을 지정해서 생성한다. 이와 관련된 정리는 다른 블로그에 잘 정리되어 있다. { 이상과 같이 RESTful 방식으로 스키마를 생성하는 자세한 방법은 Solr 도움말을 참고 하면 된다. |
스키마에 대해서 조금 더 정리하면,
적당한 편집기로 example\techproducts\solr\techproducts\conf 폴더에 있는 managed-schema 파일을 연다.
example\techproducts\solr\techproducts 폴더는 앞서 정리한 기술제품(techproducts)의 코어가 있는 폴더이고
managed-schema 파일은 코어의 스키마에 대해서 정의하는 XML 파일이다.
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="pre" type="preanalyzed" indexed="true" stored="true"/>
<field name="sku" type="text_en_splitting_tight" indexed="true" stored="true" omitNorms="true"/>
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="manu" type="text_gen_sort" indexed="true" stored="true" omitNorms="true" multiValued="false"/>
<field name="cat" type="string" indexed="true" stored="true" multiValued="true"/>
<field name="features" type="text_general" indexed="true" stored="true" multiValued="true"/>
<field name="includes" type="text_general" indexed="true" stored="true" termVectors="true" termPositions="true" termOffsets="true" />
<field name="weight" type="pfloat" indexed="true" stored="true"/>
<field name="price" type="pfloat" indexed="true" stored="true"/>
<field name="popularity" type="pint" indexed="true" stored="true" />
<field name="inStock" type="boolean" indexed="true" stored="true" />
<field name="store" type="location" indexed="true" stored="true"/>앞서 정리했던, 기술제품(techproducts)의 필드들이 정의되어 있다.
필드명(name), 색인여부(indexed), 저장여부(indexed), 필수 입력(required), 다중값여부(multiValued)등의 속성을 지정했다.
이와 관련된 정리는 다른 블로그에 잘 정리되어 있다.
영화 정보의 managed-schema 파일 (\server\solr\films)에는 이러한 정의가 없다 (Schemaless).
'서버 > 검색엔진' 카테고리의 다른 글
| 1. Solr 예제 분석 - 설치 (1) | 2020.01.12 |
|---|---|
| 2. Solr 예제 분석 - 기술제품과 검색식 (3) | 2020.01.12 |
| 4. Solr 예제 분석 - DIH (0) | 2020.01.12 |
| 1. Solr로 만드는 단순 게시판: 각종 설치 (18) | 2017.08.24 |
| 2. SolrJ 사용법 (0) | 2017.08.24 |