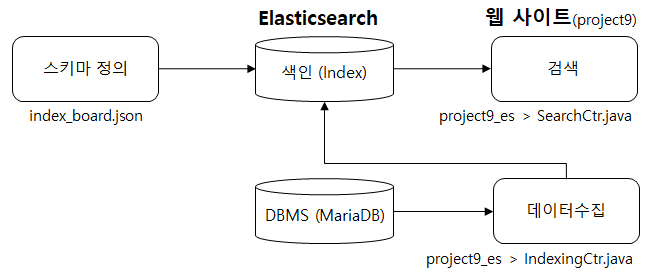
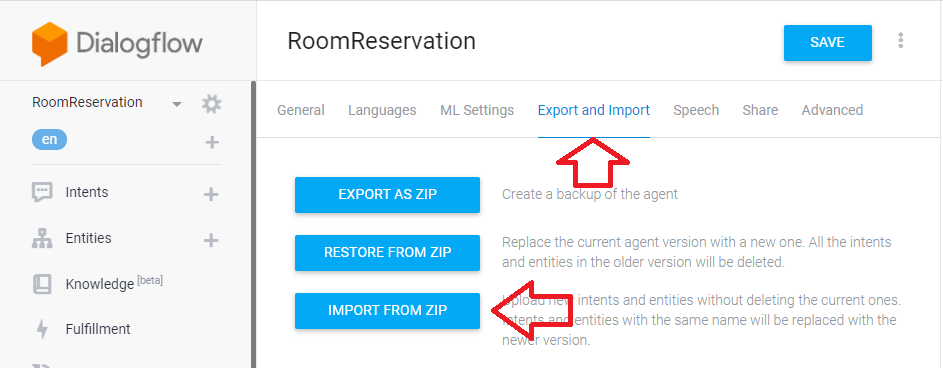
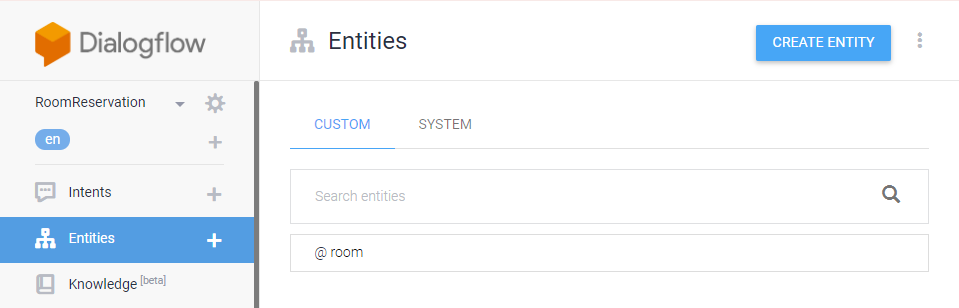
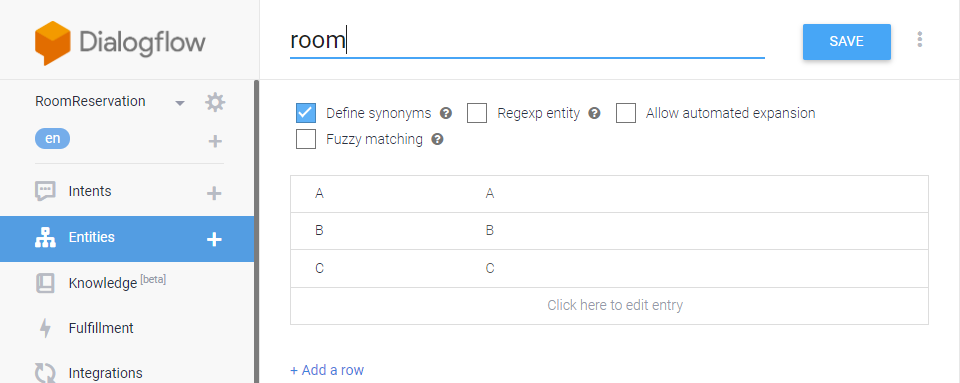
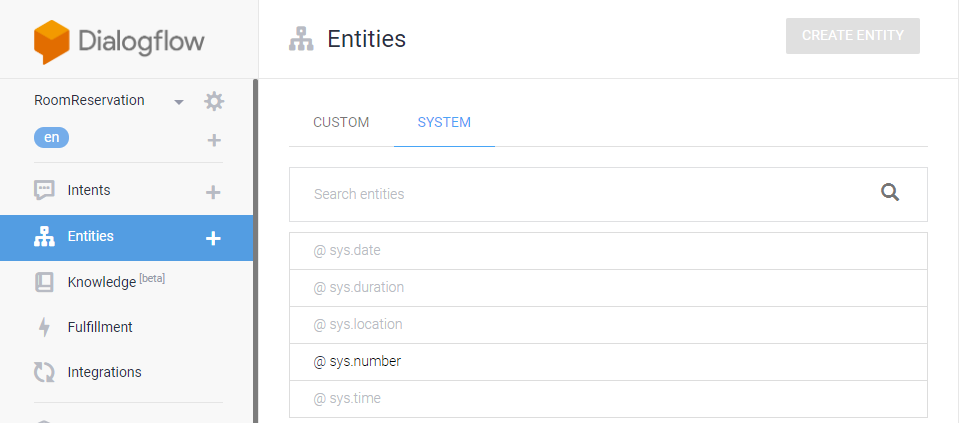
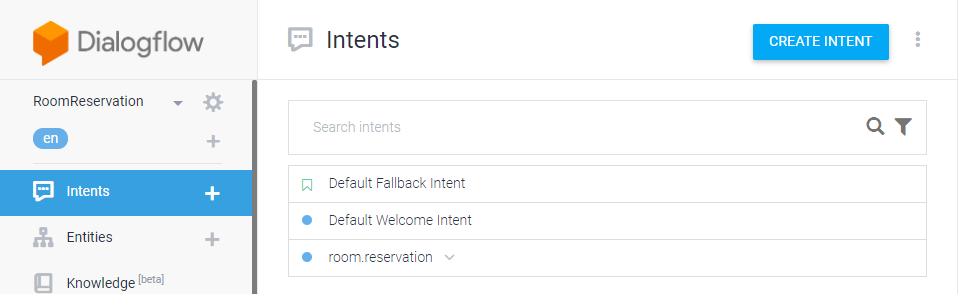
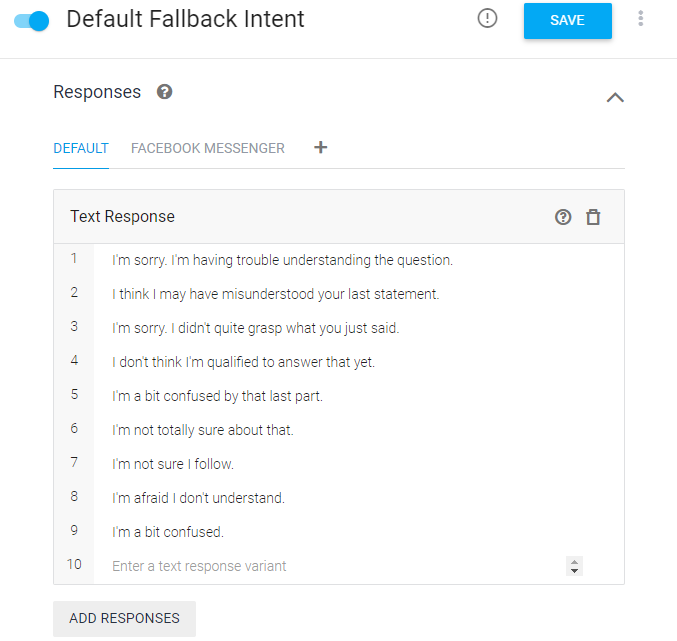
List boardlist = (List) boardSvc.selectBoards4Indexing(brdno); List replylist = (List) boardSvc.selectBoardReply4Indexing(lastVO); List filelist = (List) boardSvc.selectBoardFiles4Indexing(lastVO);
회사에서 오픈 소스 검색엔진인 Lucene을 기반으로 하는 Elasticsearch 도입을 진행하면서,
이전에 조금 다루었던 Solr (Lucene을 기반으로 하는 또 다른 검색엔진)를 개인적으로 정리 하고 있다.
둘 다 조금 부족한 형태소 분석기 (정확하게는 사전)를 이용하는데,
부족한 부분을 채우기 위해 이것 저것 시도하면서 찾은 데이터들 중에서 다른 이들에게도 중요 할만한 데이터들을 공유한다.
특히, 검색 엔진, 형태소 분석기 등의 프로그램에 대한 자료는 많이 공개되어 있어서 쉽게 구할 수 있는데,
이들을 제대로 사용할 수 있게 하는 사전에 대한 자료가 부족한 것 같다 (못 찾아서?).
이하의 데이터들을 여러 가지로 적용해서 활용 방법을 정리할 계획으로, 언제 끝날지 알 수 없어 가치 있어 보이는 데이터 리스트부터 정리한다.
유사한 맥락에서 심심풀이로 진행하는 챗봇(Dialogflow와 Rivescript/ChatScript) 제작에 도움 될 것 같아서 찾은 한국어 대화 데이터를 구할 수 있는 정보도 공유한다.
한글형태소 사전(NIADic)
국립 국어원에서 제공하는 데이터로, 약 100만건의 단어 사전 제공
“중소기업, 연구자, 일반인 등이 쉽게 NIADic을 활용하여 텍스트 분석을 수행할 수 있도록 KoNLP의 기초 형태소 사전으로 추가하여 제공”한다고 하는데 자연어 처리쪽에서 많이 사용하고, 검색엔진에 적용된 것을 보지 못해서 방법을 찾고 있다 (정보가 있으신 분 공유를 부탁드립니다).
홈페이지 하단에 있는 이메일(bigkinds@kpf.or.kr)로 연락하면, 친절한 안내와 함께 2017년에 개정된 엑셀파일을 받을 수 있다.
시소러스 사전은 조금 가공해서 유의어 사전으로 사용하고,
텍사노미 사전은 복합어 사전으로 유용할 것 같아서 가공해서 사용할 계획이다.
[경희대]를 Lucene 기반 검색엔진에서 어떤 형태소 분석기로 분석하면 [경희]와 [대]로 색인. [경희대]를 사용자 사전에 추가하면 [경희대]로 색인은 되지만, [경희대학교]가 [경희대]와 [학교]로 색인. [경희대학교]를 사용자 사전에 추가하면, 공백 차이로 [경희 대학교]가 색인되지 않음(검색되지 않음) 따라서, [경희대]를 사용자 사전에 추가하고, [경희대학교]와 [경희 대학교]를 복합명사 사전에 등록해야 [경희대], [경희대학교], [경희 대학교](실제로는 [경희], [대학교])로 색인. => 모든 학교와 조직들을 이런식으로 사전에 등록할 수 없는데, 텍사노미 사전에 이러한 내용이 일부 포함되어 있어서 가공하여 사용할 계획이다.
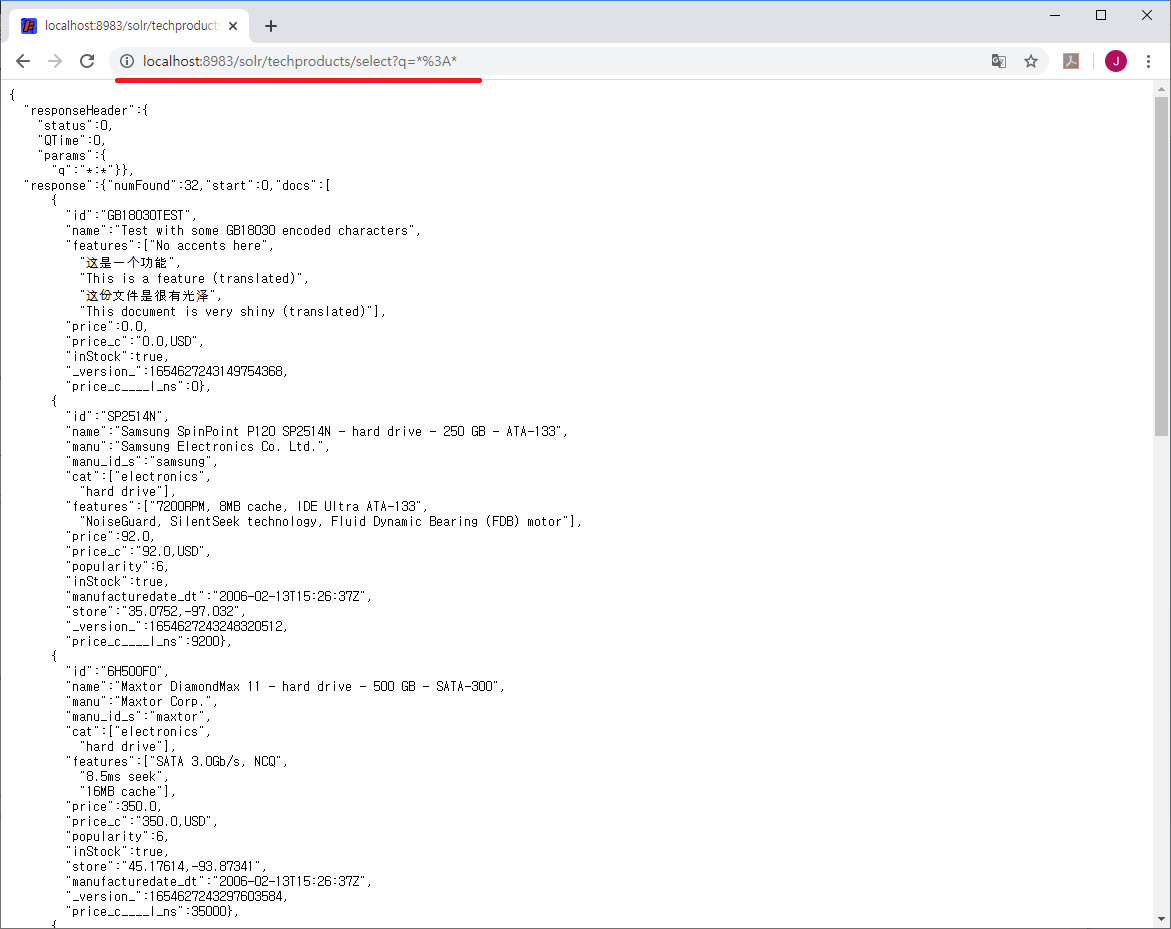
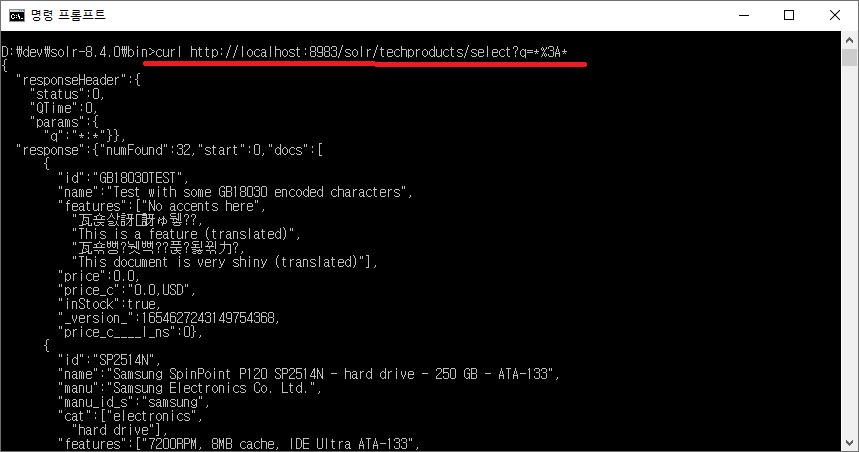
즉, URL의 내용을 수정해서 다른 웹브라우저나 탭, 프로그램curl, wget, PostMan등에서 사용할 수 있다.
URL의 내용을 정리하면,
http://localhost:8983/solr은 Solr 검색 엔진 서버 주소이고
techproducts는 데이터를 저장하는 코어
select는 데이터 조회를 의미한다.
q는 Query, 즉 검색식을 의미하며 *:* (%3A = : )
콜론(:) 앞의 *는 모든 필드를, 뒤의 *는 모든 값을 의미하는 것으로 모든 데이터를 조회한다는 의미가 된다.
(뒤의 * 대신에 찾고자 하는 값을 지정해서 실행하면, 모든 필드에서 지정한 값을 찾는 검색이 된다.)
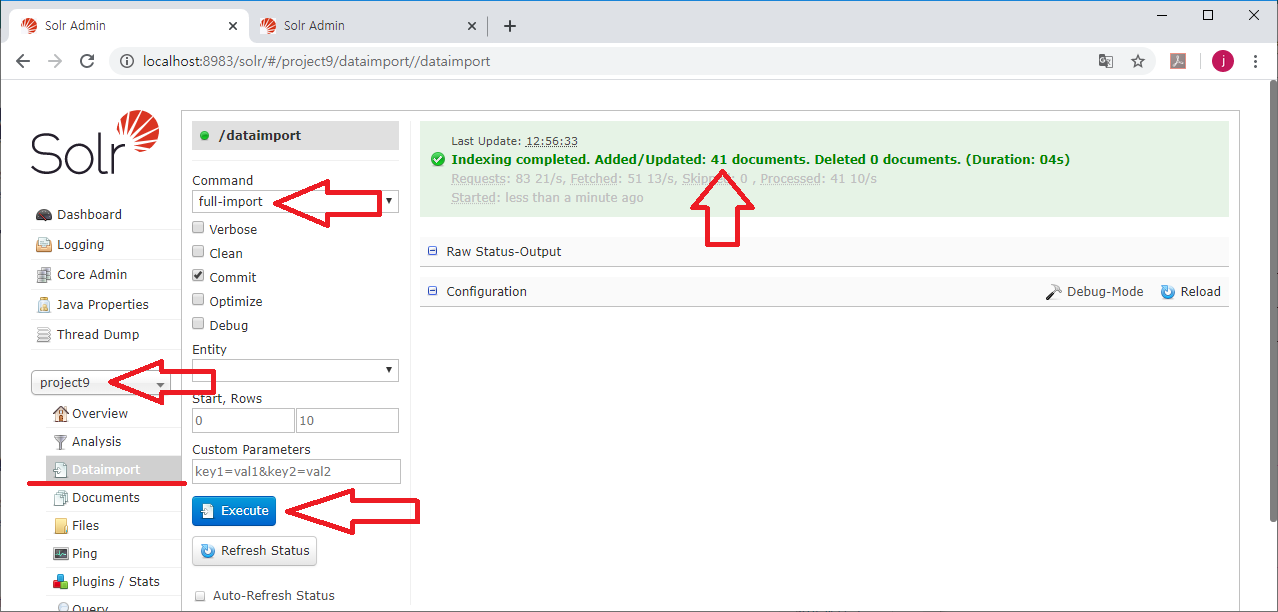
저장된 데이터가 32건이니 모든 데이터는 32건이 출력될 것 같지만 10개만 출력된다.
전체 데이터를 조회하는 경우에는 알아서 10개만 반환된다.
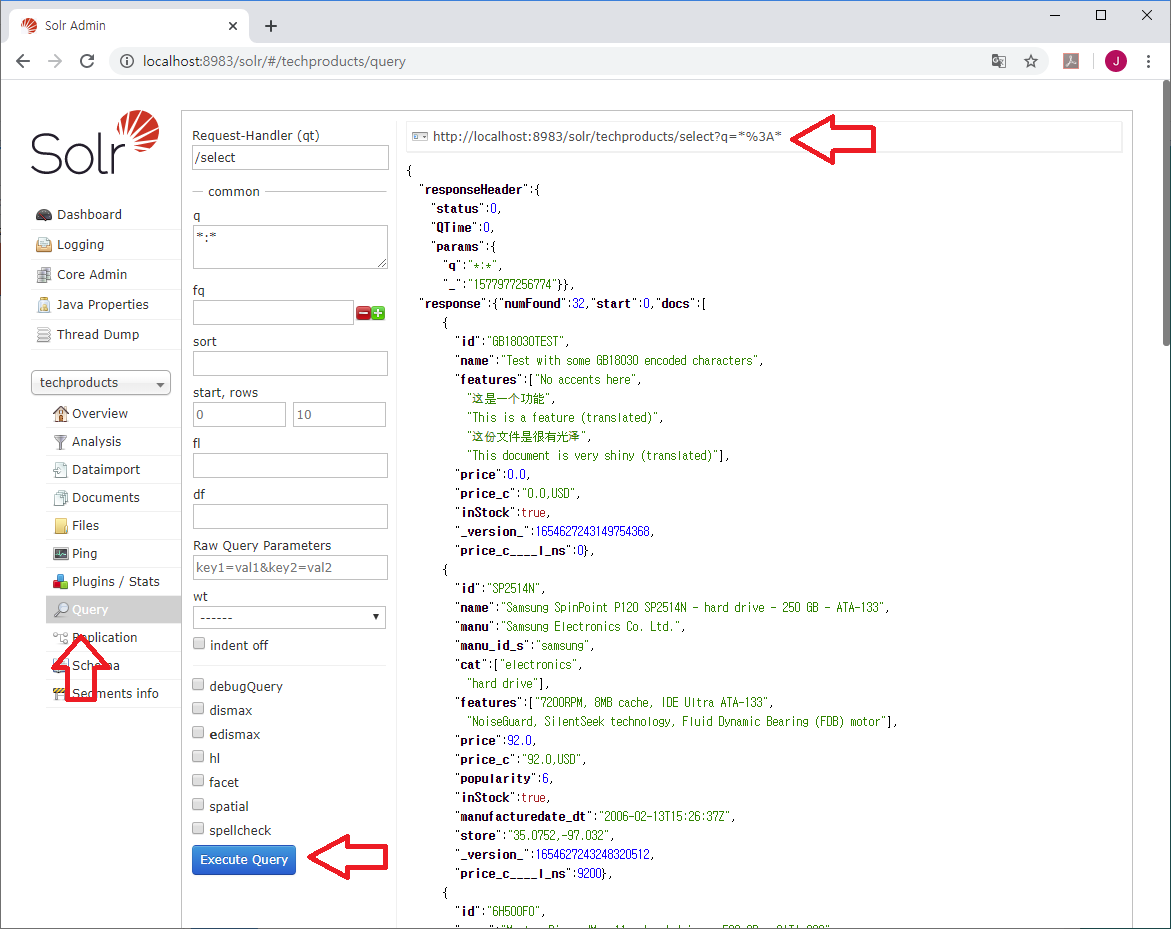
이 URL은 앞서의 Query 화면에서 (http://localhost:8983/solr/#/techproducts/query)
Execute Query 버튼을 클릭하면서 자동으로 생성된 것으로,
"Query" 메뉴는 검색식을 잘 모르는 초보자들이 검색 조건을 쉽게 만들어서 테스트 해 볼 수 있는 메뉴이다.
개발자들이 각 검색 조건에 값을 지정하고 실행하면, 즉시 실행 결과를 확인할 수 있고
Java와 같은 개발 언어에서 RESTful로 호출해서 사용할 수 있는 URL을 알려주는 것이다.
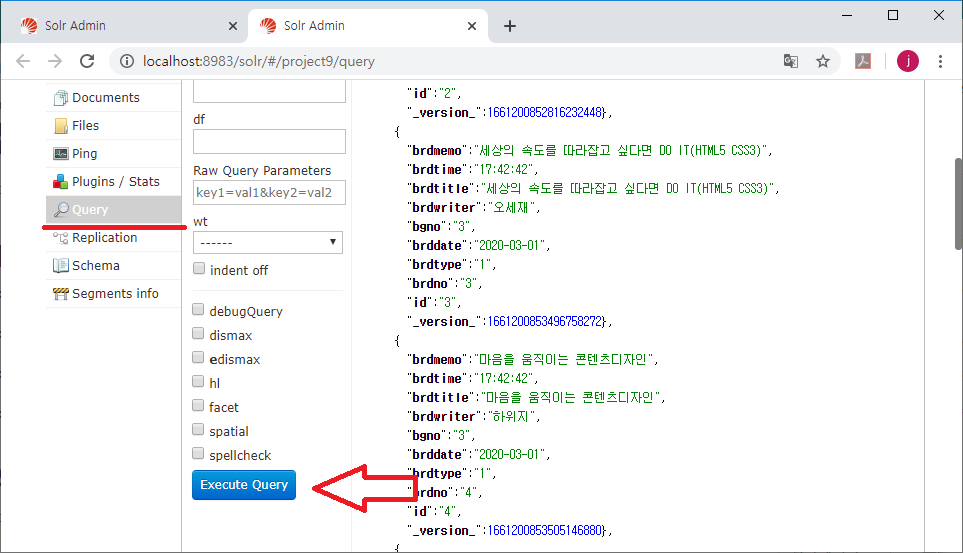
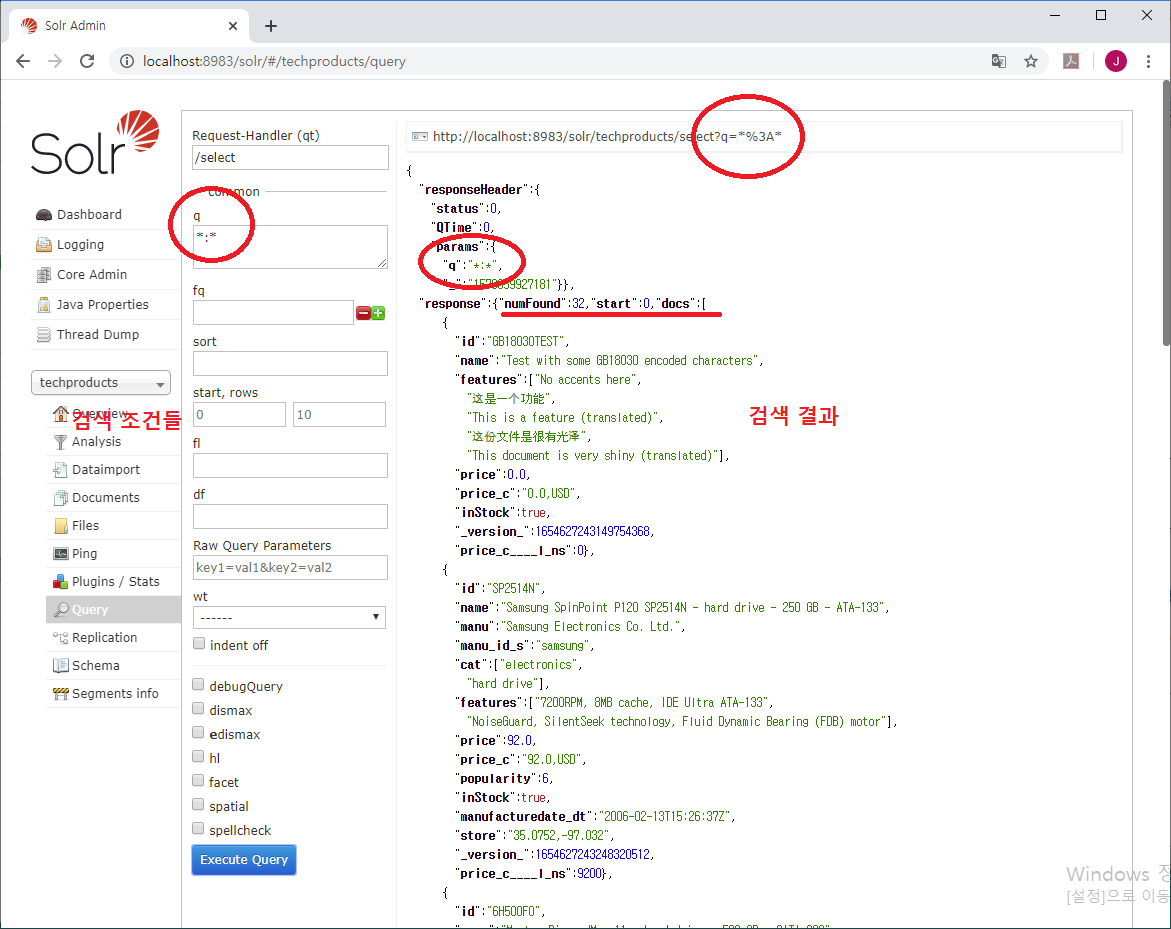
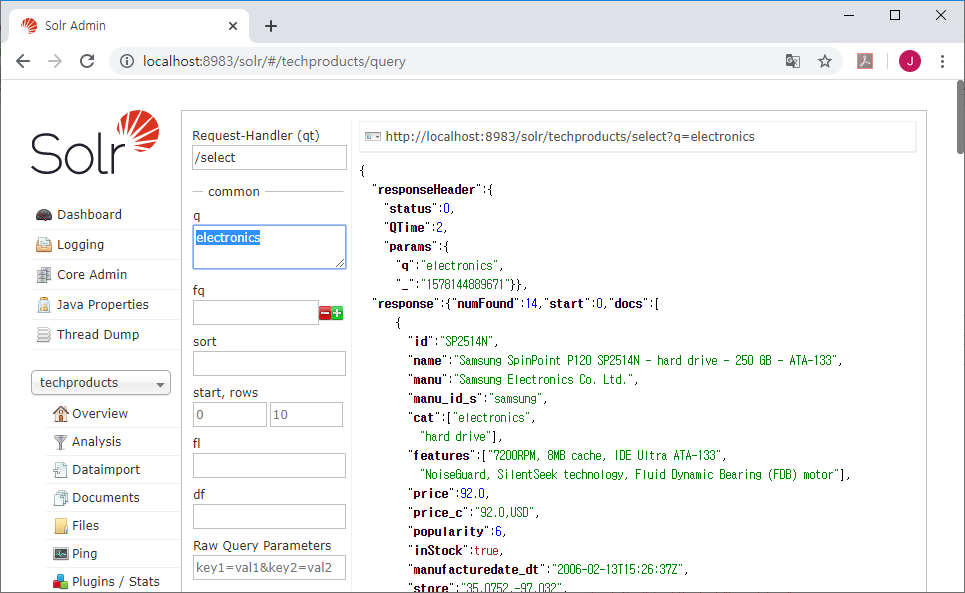
위 그림에서 동그라미로 표시된 q *:*를 보면
좌측의 q *:*이 조건식을 입력한 것이고
우측 상단의 url이 Query 페이지에서 자동으로 생성된 실행 명령어(URL - q *:*)이고
우측 중앙에 있는 responseHeader에
Solr가 실행한 결과를 반환하면서 무엇을 실행했는지(params, q *:*)가 표시되어 있다.
response에 numFound가 찾은 전체 개수이고, start가 몇번째 것 부터 가지고 온 것인지 표시한 것이다.
좌측의 검색 조건 입력부분에서 start 값을 변경하면 response의 값도 동일하게 바뀐다.
즉, 검색한 데이터 중 몇 번째 부터(start), 몇 개(rows) 를 가지고 오라고 지정하는 것이다.
페이징(Paging)처리를 위한 것이다.
docs 다음의 배열( [ ] )은 찾은 데이터의 필드 이름과 필드 값들이 Json 형태로 출력된다.
id, name, features, price, price_c 등의 필드 값이 출력된다.
검색 조건들을 지정하는 부분에는 q, start, rows외에도 fq(Filter Query), Sort(정렬), fl (반환할 필드 리스트), df (default search field 기본 검색 필드), wt (writer type 결과 표시 방법 Json, XML등) 등의 설정을 지정해서 검색 할 수 있다.
보다 자세한 내용은 Solr 문서를 읽어보길 바라고 (값 넣고 실행해 보면 대충 파악 가능), 다른 블로그에 정리된 내용을 참고 해도 된다.