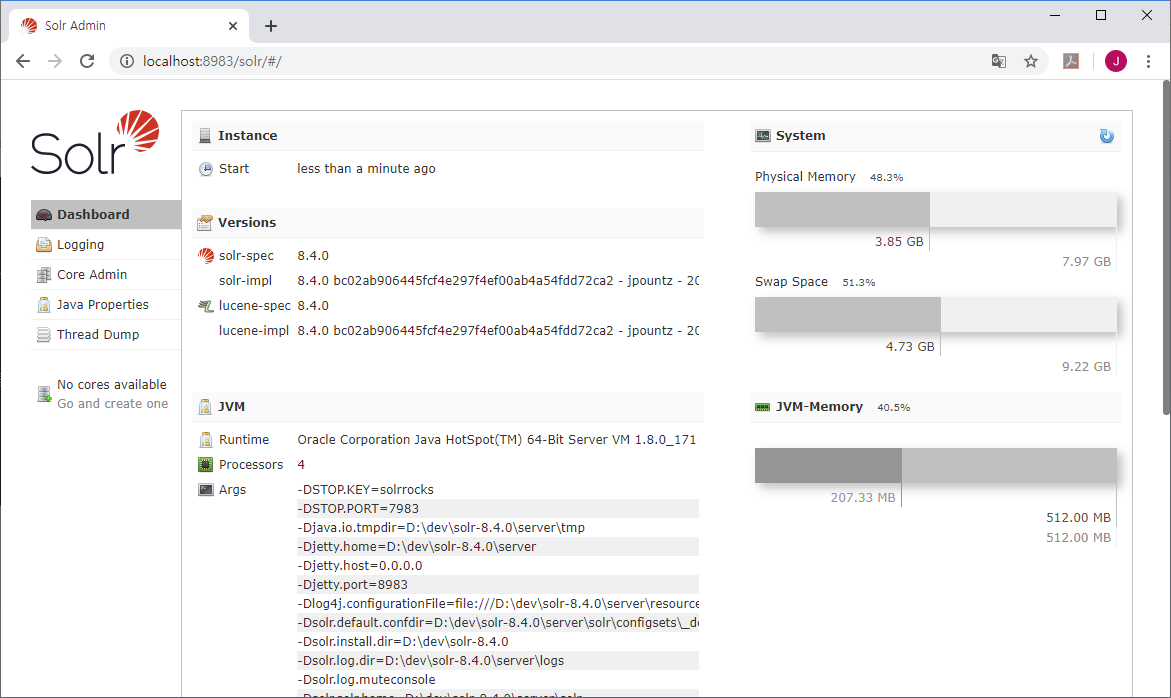
회사에서 오픈 소스 검색엔진인 Lucene을 기반으로 하는 Elasticsearch 도입을 진행하면서,
이전에 조금 다루었던 Solr (Lucene을 기반으로 하는 또 다른 검색엔진)를 개인적으로 정리 하고 있다.
둘 다 조금 부족한 형태소 분석기 (정확하게는 사전)를 이용하는데,
부족한 부분을 채우기 위해 이것 저것 시도하면서 찾은 데이터들 중에서 다른 이들에게도 중요 할만한 데이터들을 공유한다.
특히, 검색 엔진, 형태소 분석기 등의 프로그램에 대한 자료는 많이 공개되어 있어서 쉽게 구할 수 있는데,
이들을 제대로 사용할 수 있게 하는 사전에 대한 자료가 부족한 것 같다 (못 찾아서?).
이하의 데이터들을 여러 가지로 적용해서 활용 방법을 정리할 계획으로, 언제 끝날지 알 수 없어 가치 있어 보이는 데이터 리스트부터 정리한다.
유사한 맥락에서 심심풀이로 진행하는 챗봇(Dialogflow와 Rivescript/ChatScript) 제작에 도움 될 것 같아서 찾은 한국어 대화 데이터를 구할 수 있는 정보도 공유한다.
한글형태소 사전(NIADic)
국립 국어원에서 제공하는 데이터로, 약 100만건의 단어 사전 제공
“중소기업, 연구자, 일반인 등이 쉽게 NIADic을 활용하여 텍스트 분석을 수행할 수 있도록 KoNLP의 기초 형태소 사전으로 추가하여 제공”한다고 하는데 자연어 처리쪽에서 많이 사용하고, 검색엔진에 적용된 것을 보지 못해서 방법을 찾고 있다 (정보가 있으신 분 공유를 부탁드립니다).
홈페이지 하단에 있는 이메일(bigkinds@kpf.or.kr)로 연락하면, 친절한 안내와 함께 2017년에 개정된 엑셀파일을 받을 수 있다.
시소러스 사전은 조금 가공해서 유의어 사전으로 사용하고,
텍사노미 사전은 복합어 사전으로 유용할 것 같아서 가공해서 사용할 계획이다.
[경희대]를 Lucene 기반 검색엔진에서 어떤 형태소 분석기로 분석하면 [경희]와 [대]로 색인. [경희대]를 사용자 사전에 추가하면 [경희대]로 색인은 되지만, [경희대학교]가 [경희대]와 [학교]로 색인. [경희대학교]를 사용자 사전에 추가하면, 공백 차이로 [경희 대학교]가 색인되지 않음(검색되지 않음) 따라서, [경희대]를 사용자 사전에 추가하고, [경희대학교]와 [경희 대학교]를 복합명사 사전에 등록해야 [경희대], [경희대학교], [경희 대학교](실제로는 [경희], [대학교])로 색인. => 모든 학교와 조직들을 이런식으로 사전에 등록할 수 없는데, 텍사노미 사전에 이러한 내용이 일부 포함되어 있어서 가공하여 사용할 계획이다.
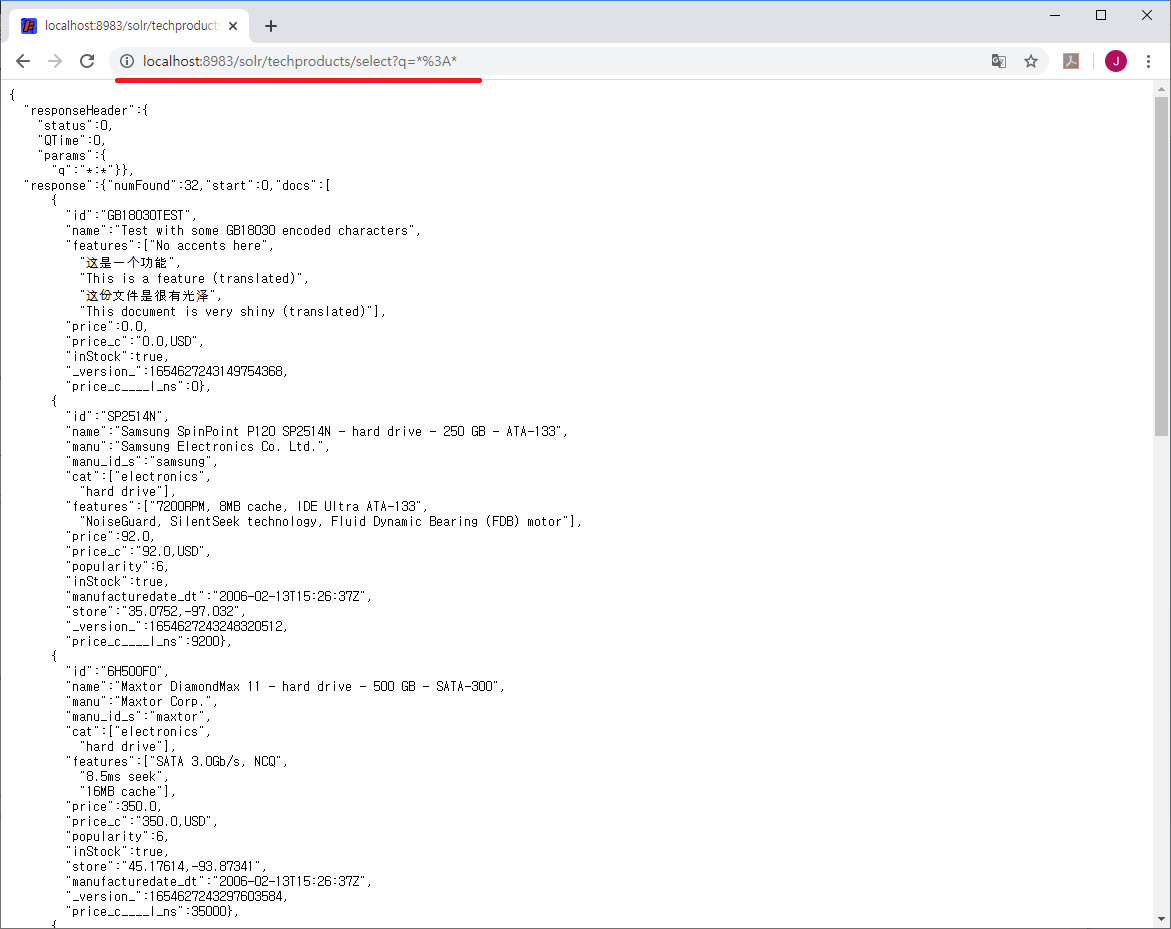
즉, URL의 내용을 수정해서 다른 웹브라우저나 탭, 프로그램curl, wget, PostMan등에서 사용할 수 있다.
URL의 내용을 정리하면,
http://localhost:8983/solr은 Solr 검색 엔진 서버 주소이고
techproducts는 데이터를 저장하는 코어
select는 데이터 조회를 의미한다.
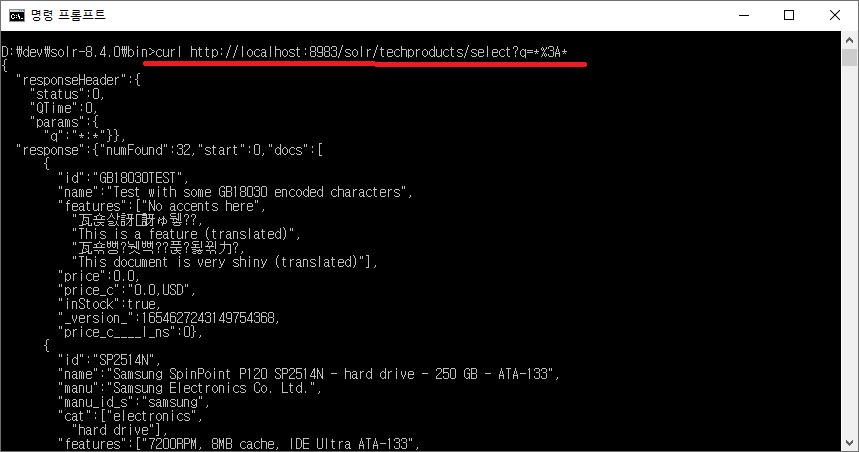
q는 Query, 즉 검색식을 의미하며 *:* (%3A = : )
콜론(:) 앞의 *는 모든 필드를, 뒤의 *는 모든 값을 의미하는 것으로 모든 데이터를 조회한다는 의미가 된다.
(뒤의 * 대신에 찾고자 하는 값을 지정해서 실행하면, 모든 필드에서 지정한 값을 찾는 검색이 된다.)
저장된 데이터가 32건이니 모든 데이터는 32건이 출력될 것 같지만 10개만 출력된다.
전체 데이터를 조회하는 경우에는 알아서 10개만 반환된다.
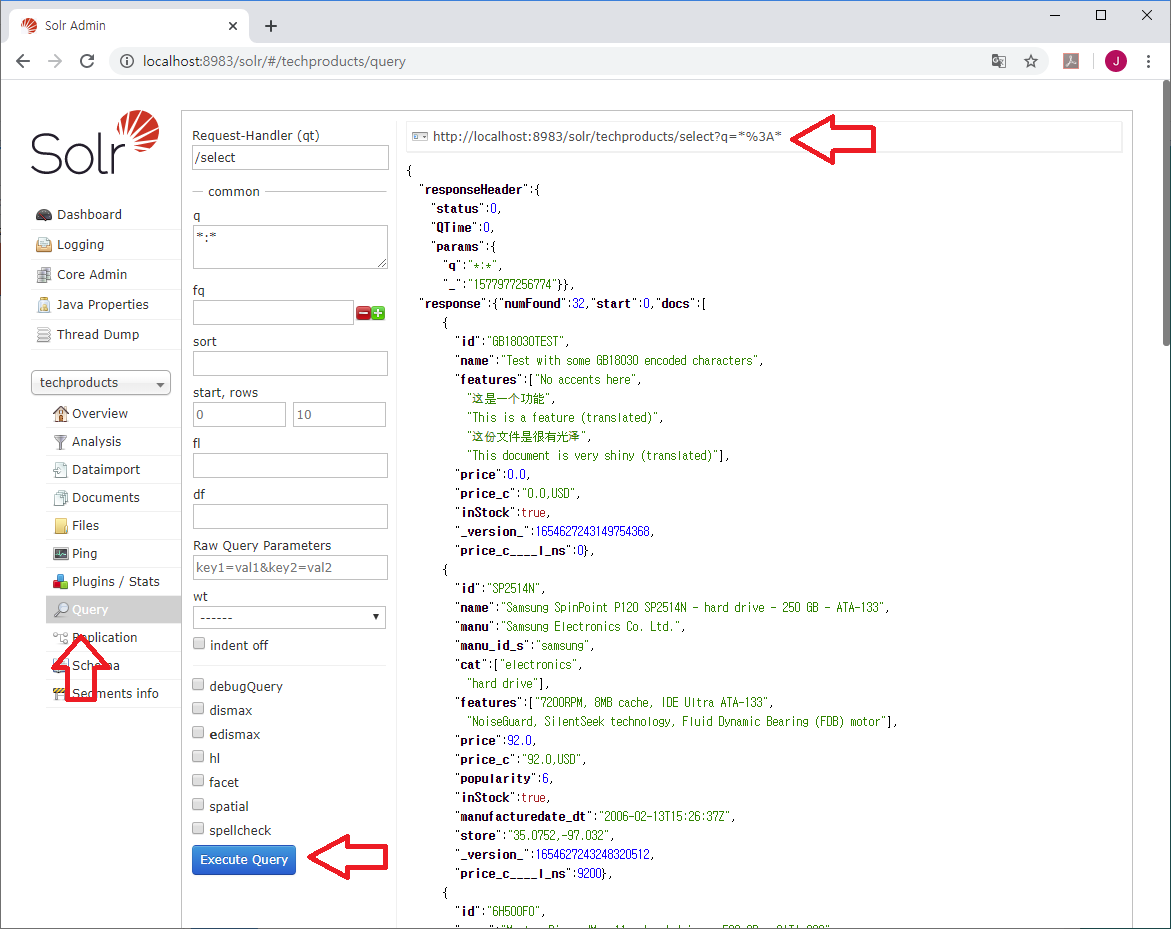
이 URL은 앞서의 Query 화면에서 (http://localhost:8983/solr/#/techproducts/query)
Execute Query 버튼을 클릭하면서 자동으로 생성된 것으로,
"Query" 메뉴는 검색식을 잘 모르는 초보자들이 검색 조건을 쉽게 만들어서 테스트 해 볼 수 있는 메뉴이다.
개발자들이 각 검색 조건에 값을 지정하고 실행하면, 즉시 실행 결과를 확인할 수 있고
Java와 같은 개발 언어에서 RESTful로 호출해서 사용할 수 있는 URL을 알려주는 것이다.
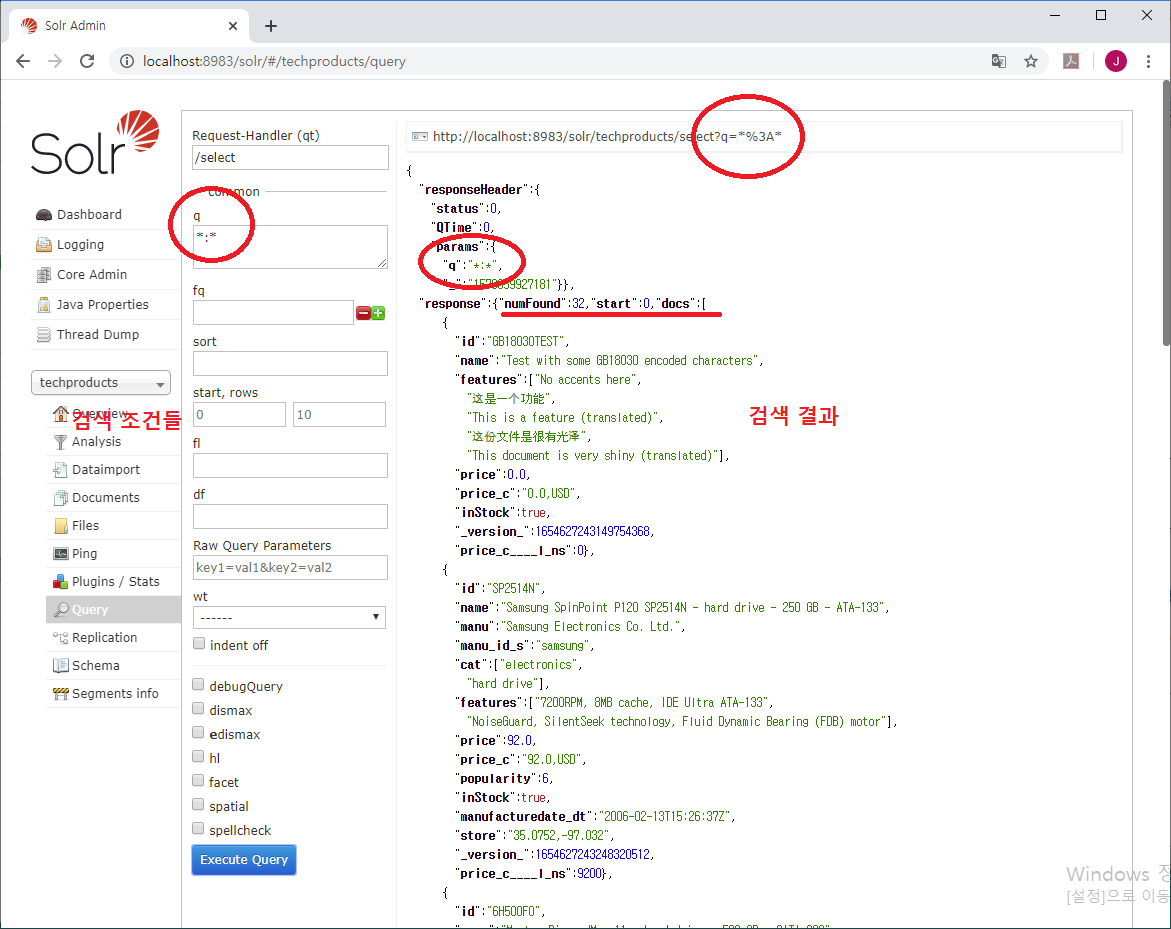
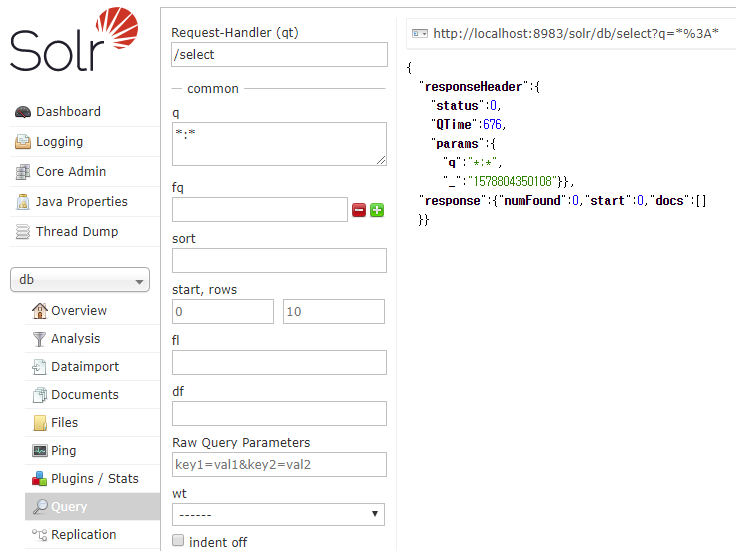
위 그림에서 동그라미로 표시된 q *:*를 보면
좌측의 q *:*이 조건식을 입력한 것이고
우측 상단의 url이 Query 페이지에서 자동으로 생성된 실행 명령어(URL - q *:*)이고
우측 중앙에 있는 responseHeader에
Solr가 실행한 결과를 반환하면서 무엇을 실행했는지(params, q *:*)가 표시되어 있다.
response에 numFound가 찾은 전체 개수이고, start가 몇번째 것 부터 가지고 온 것인지 표시한 것이다.
좌측의 검색 조건 입력부분에서 start 값을 변경하면 response의 값도 동일하게 바뀐다.
즉, 검색한 데이터 중 몇 번째 부터(start), 몇 개(rows) 를 가지고 오라고 지정하는 것이다.
페이징(Paging)처리를 위한 것이다.
docs 다음의 배열( [ ] )은 찾은 데이터의 필드 이름과 필드 값들이 Json 형태로 출력된다.
id, name, features, price, price_c 등의 필드 값이 출력된다.
검색 조건들을 지정하는 부분에는 q, start, rows외에도 fq(Filter Query), Sort(정렬), fl (반환할 필드 리스트), df (default search field 기본 검색 필드), wt (writer type 결과 표시 방법 Json, XML등) 등의 설정을 지정해서 검색 할 수 있다.
보다 자세한 내용은 Solr 문서를 읽어보길 바라고 (값 넣고 실행해 보면 대충 파악 가능), 다른 블로그에 정리된 내용을 참고 해도 된다.
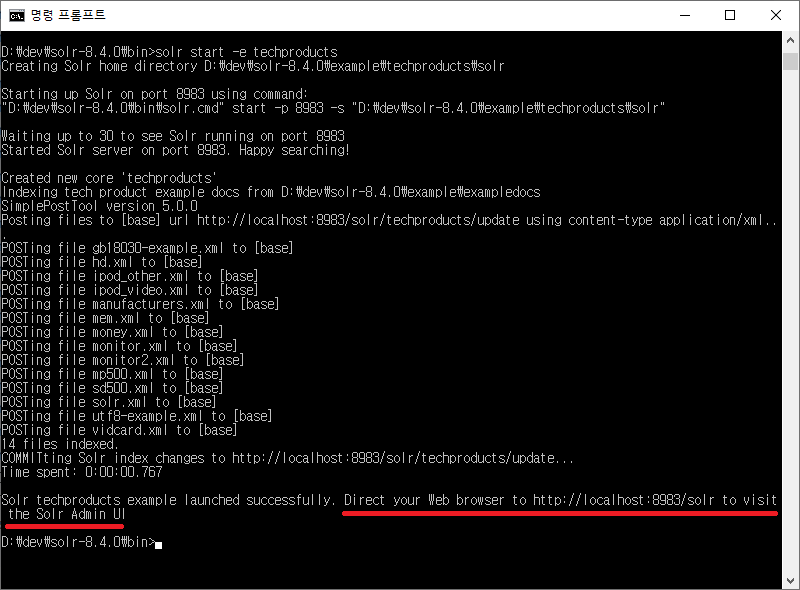
Solr 예제 폴더(example\example-DIH\)에는 atom, db, mail 등의 데이터 예제가 있다.
이 중에서 db (hsqldb) 예제를 정리한다.
주의: SQL이나 데이터 베이스에 대한 개념이 없다면, 다음 내용을 이해하는데 어려울 수 있다.
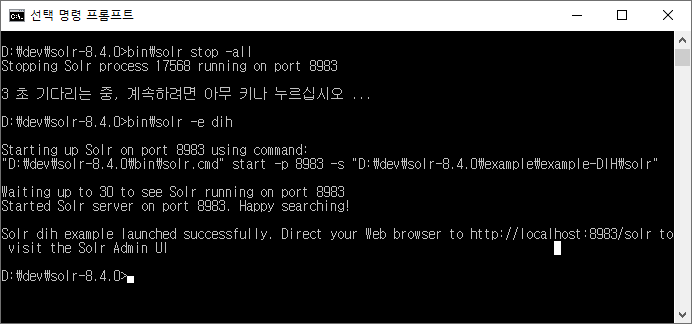
실행 중인 Solr를 멈추고,
bin\solr stop -all
다음 명령어로 DIH 예제를 실행한다.
bin\solr -e dih
Solr 관리자 화면으로 접속하면 5개의 코어가 생성된 것을 확인할 수 있다.
이 중에서 db 코어를 선택하고, Query 화면에서 데이터를 조회하면 비어 있다 (numFound=0).
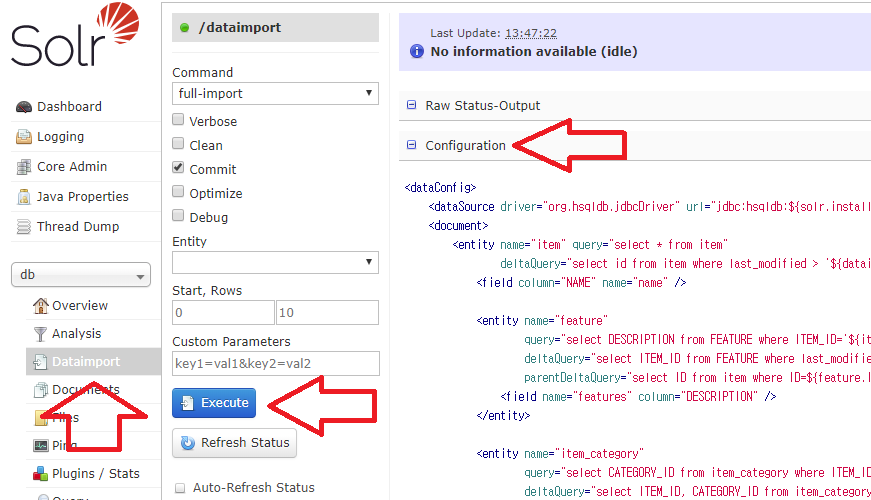
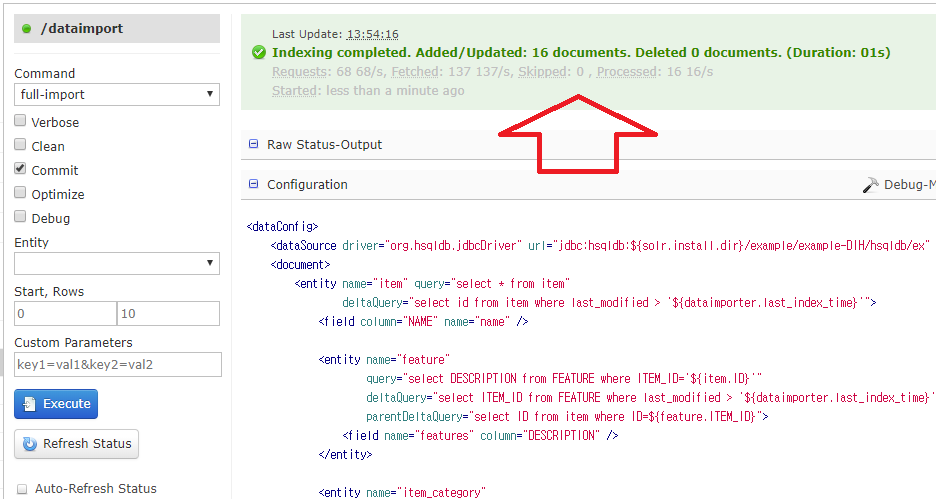
Solr 관리자 화면의 Dataimport 메뉴를 선택한 후, 화면 오른쪽의 Configuration을 클릭해서 실행할 SQL문을 확인한다.
중앙의 실행(Execute) 버튼을 클릭해서, 이 SQL문을 실행한다.
실행(Execute) 버튼을 클릭하고, Auto-Refresh Status를 체크해서 자동으로 갱신되게 하거나,
Refresh Status를 클릭해서 수동으로 갱신해서 처리 결과를 확인한다.
녹색 배경으로 16개의 데이터(document)가 저장되었다는 메시지가 나타나면, 잘 실행된 것이다.
Query 메뉴에서 저장된 데이터를 확인 할 수 있다.
앞서 정리한 기술 제품의 내용과 동일한 데이터로,
기술 제품 예제는 이 데이터 베이스의 내용을 XML로 만든 파일을 저장한 것이다.
간단하게 db 예제 사용법을 정리했고, 상세한 내용을 정리한다.
예제로 사용된 db는 hsqldb이지만
Dataimport 메뉴에서 확인한 다음의 SQL문을 보면 기본적인 SQL문만 사용되었기 때문에 hsqldb라는 것에 부담을 가질 필요는 없다.
<dataConfig>
<dataSource driver="org.hsqldb.jdbcDriver" url="jdbc:hsqldb:${solr.install.dir}/example/example-DIH/hsqldb/ex" user="sa" />
<document>
<entity name="item" query="select * from item"
deltaQuery="select id from item where last_modified > '${dataimporter.last_index_time}'">
<field column="NAME" name="name" />
<entity name="feature"
query="select DESCRIPTION from FEATURE where ITEM_ID='${item.ID}'"
deltaQuery="select ITEM_ID from FEATURE where last_modified > '${dataimporter.last_index_time}'"
parentDeltaQuery="select ID from item where ID=${feature.ITEM_ID}">
<field name="features" column="DESCRIPTION" />
</entity>
<entity name="item_category"
query="select CATEGORY_ID from item_category where ITEM_ID='${item.ID}'"
deltaQuery="select ITEM_ID, CATEGORY_ID from item_category where last_modified > '${dataimporter.last_index_time}'"
parentDeltaQuery="select ID from item where ID=${item_category.ITEM_ID}">
<entity name="category"
query="select DESCRIPTION from category where ID = '${item_category.CATEGORY_ID}'"
deltaQuery="select ID from category where last_modified > '${dataimporter.last_index_time}'"
parentDeltaQuery="select ITEM_ID, CATEGORY_ID from item_category where CATEGORY_ID=${category.ID}">
<field column="DESCRIPTION" name="cat" />
</entity>
</entity>
</entity>
</document>
</dataConfig>
SQL이 나열된 XML은 Dataimport 메뉴에서 확인 할 수도 있고,
db-data-config.xml 설정(example\example-DIH\solr\db\conf)파일에서도 확인/ 수정 할 수 있다.
참고: Solr의 기본 설정 파일인 solrconfig.xml에서 다음과 같이 db-data-config.xml 을 지정해야 db-data-config.xml 에서 위와 같은 내용을 작성해서 사용할 수 있다.
<entity name="item" query="select * from item"
~~ 생략 ~~
<entity name="feature"
query="select DESCRIPTION from FEATURE where ITEM_ID='${item.ID}'"
deltaQuery="select ITEM_ID from FEATURE where last_modified > '${dataimporter.last_index_time}'"
parentDeltaQuery="select ID from item where ID=${feature.ITEM_ID}">
<field name="features" column="DESCRIPTION" />
</entity>
</entity>
ERD의 관계(Relation)를 태그의 하위 계층으로 표현하는 것이다.
특성(FEATURE) 테이블에서 데이터를 가지고 오는 것은 제품(ITEM) 테이블에서 가지고 오는 것과 동일하다.
처음에는(query) 테이블의 모든 데이터를 가지고 오고,
이후에는(deltaQuery) 증가된 데이터만 가지고 온다. last_modified > '${dataimporter.last_index_time}
여기에 추가적인 것이 parentDeltaQuery로 부모가 누구인지 지정하는 부분이 있다.
가지고 온 데이터를 누구에게 넣어줄 것인지를 지정하는 것으로,
제품(ITEM) 테이블에서 ID 필드가 기본키(paimary key)로 특성(FEATURE)테이블의 ITEM_ID 필드로 관계가 설정되어 있어, 이 값으로 서로를 식별하게 된다.
select ID from item where ID=${feature.ITEM_ID}
즉, 특성 테이블의 값을 가지고 온 후(feature), 제품 테이블의 해당하는 ID를 찾아서,
특성의 값(DESCRIPTION)을 features로 저장(색인)한다.
<field name="features" column="DESCRIPTION" />
주의: item(최상위 entity)에서도 field 태그를 이용해서 NAME을 name으로 저장하도록 지정했다.
색인으로 저장할 컬럼들은 모두 field 태그로 지정해야 하고, managed-schema에 정의해야 한다.
DIH에서는 managed-schema에 지정되지 않은 컬럼은 저장되지 않는다.
앞서 정리한 Shemaless가 적용되지 않는 것 같다.
parentDeltaQuery로 표현된 방식은 중요한 개념이라 다시 정리하면,
일반적인 S/W 개발에서는 제품(ITEM) 테이블에서 데이터를 가지고 오고,
각각의 행에 있는 제품의 특성(ID) 필드의 값에 맞는 것을 특성(FEATURE) 테이블에서 찾아서
해당하는 설명(DESCRIPTION)을 가지고 오게 작성한다.
그리고 SQL로 표현하면 다음과 같다.
select a.*, (select DESCRIPTION from FEATURE where ITEM_ID=a.ID) as features from ITEM a
주의: 제품(ITEM)과 특성(FEATURE)의 관계는 1:n 이기 때문에 이 SQL문을 그대로 쓰면 오류가 발생해서 실제론 stragg 처리를 해야 한다.
일반적인 S/W 개발에서는 제품(ITEM) 데이터를 가지고 오면서, 필요한 구성원 데이터(특성-FEATURE)을 가지고 오도록 작성한다.
(모 상용 검색엔진이 이런식으로 사용한다.)
이 개념과 반대로, 예제에서는 제품(ITEM) 데이터를 가지고 와서 저장하고
필요한 구성원 데이터(FEATURE)를 가지고 와서 저장된 제품(ITEM)에 넣어주는 방식으로 작성되었다.
이렇게 하는 이유는 제품(ITEM)과 특성(FEATURE) 테이블로 설명하는 것은 부족한 것 같아서 게시판 예제로 정리한다.
게시판에 게시물이 있고(post), 하나의 게시물에 여러 개의 댓글(reply)이 달린다.
일반적인 S/W 개발 방식으로 데이터를 추출하면, 게시물이 색인 될 때의 댓글도 같이 색인하면 된다.
하지만, 색인 된 이후에 추가된 댓글들은 색인하기 어렵다.
따라서, 게시물은 게시물 데로 색인하고, 댓글은 댓글데로 색인해서
추가 댓글이 있으면 추출해서 해당 게시물에 넣어주는 것(parentDeltaQuery)이 더 좋은 방식일 것이다.
종류(category, item_category)도 동일한데, 연관 테이블(Association Table)이 있어서 좀 더 복잡하다.
주의 1: 필드 정의에서 multiValued를 true로 지정했다. 필드 지정을 하지 않으면 기본값이 true 이기 때문이고, 따라서 게시판 예제에서 brdtitle[0]}, brdwriter[0]등과 같이 사용한다. false이면 brdtitle, brdwriter등으로 사용한다.
주의 2: 필드 정의에서 brddate를 문자열로 정의하였다. 필드 지정을 하지 않으면 tdates로 지정된다. 게시판 예제는 필드 지정없이 사용하는 것을 기본으로 하기 때문에 위와 같이 문자열로 지정한 경우 jsp 파일에서 formatDate를 사용한 것을 모두 다음과 같이 수정하여야 한다.
string으로 지정한 경우: <fmt:formatDate pattern = "yyyy-MM-dd" value = "${listview.brddate[0]}" />
tdates로 지정한 경우: <c:out value="${listview.brddate}"/>