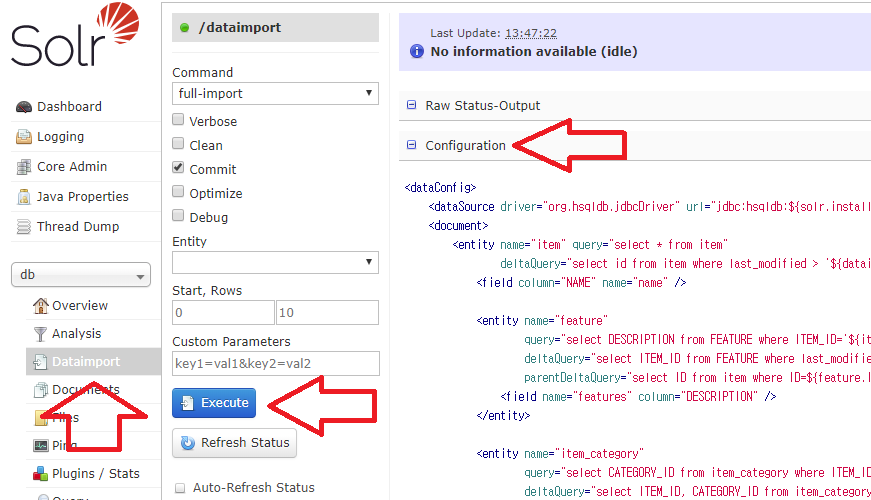
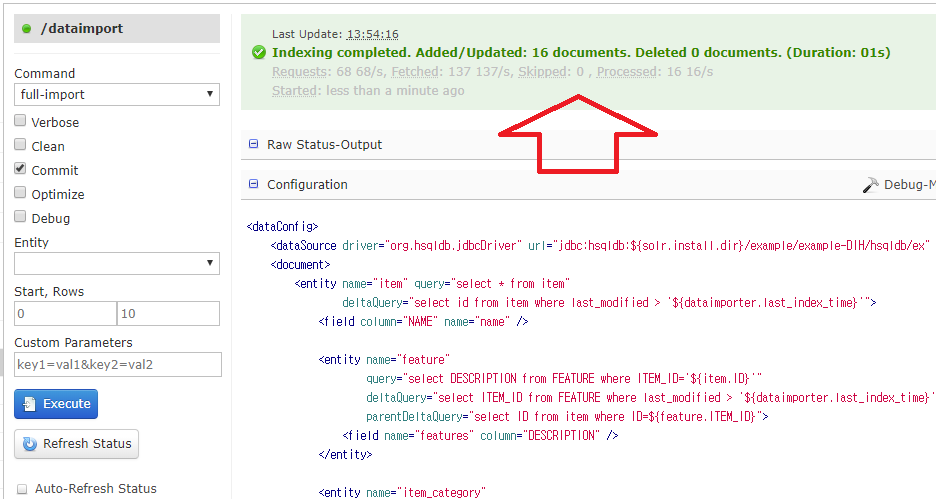
앞서서 Solr의 기술 제품 예제를 실행시켜봤다.
여기서는 Solr 예제 사이트에 있는 몇 가지 검색(Search - Query) 방법을 정리한다.
- 설치
- 기술제품과 검색식
- 스키마(Schema)
- DIH (Data Import Handler)
앞서 정리한 것과 같이, 다음 명령어로 Solr 예제 중 기술 제품을 실행한다.
bin\solr start -e techproducts
첫 번째 검색은 한 단어 검색(Search for a Single Term)이다.
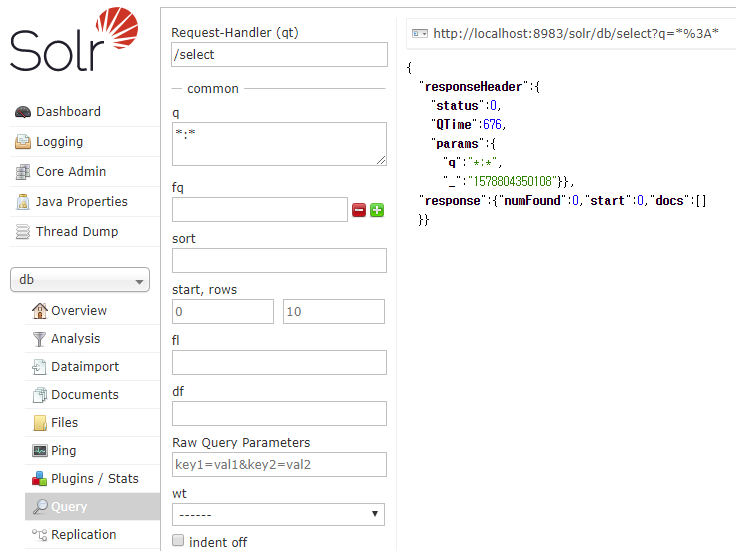
Solr 관리자 페이지에서 techproducts 코어를 선택하고, Query 메뉴를 선택해서 검색을 할 수 있도록 한다.
익숙해지면 웹 브라우저, curl, Postman 등에서 URL로 지정해서 검색하는 것이 편리하다.
다음 그림과 같이 Query 메뉴를 실행한 화면에서
q 입력상자에 electronics을 입력하고 실행 버튼(Execute Query)을 클릭해서 검색을 실행한다.
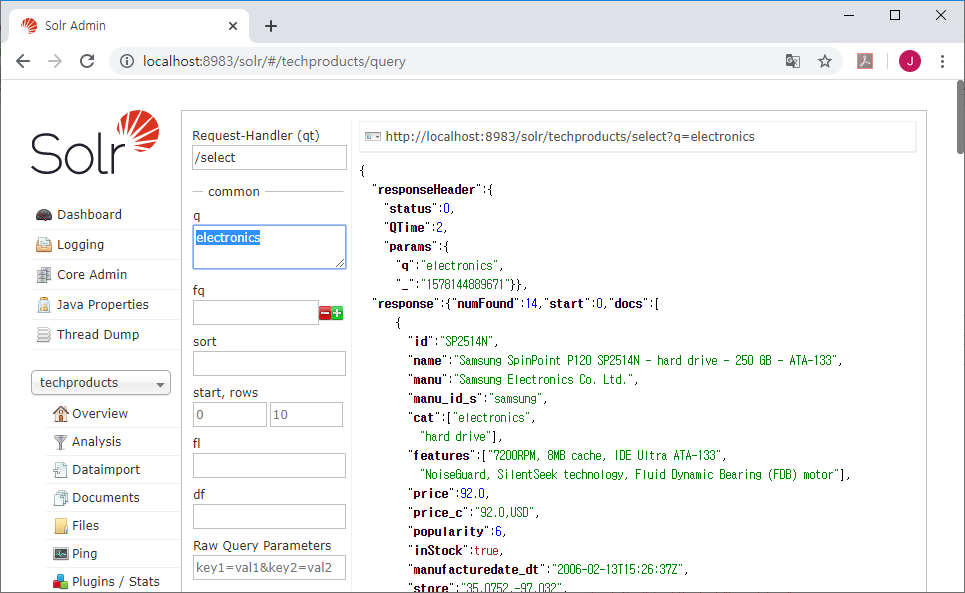
q의 기본 입력값은 *:*로, 콜론(:) 앞의 *는 모든 필드, 뒤의 *는 모든 값을 의미한다.
따라서 모든 필드에 대해서 특정한 값을 조회하면 *:electronics 으로 입력해야 할 것 같지만, electronics 만 사용한다.
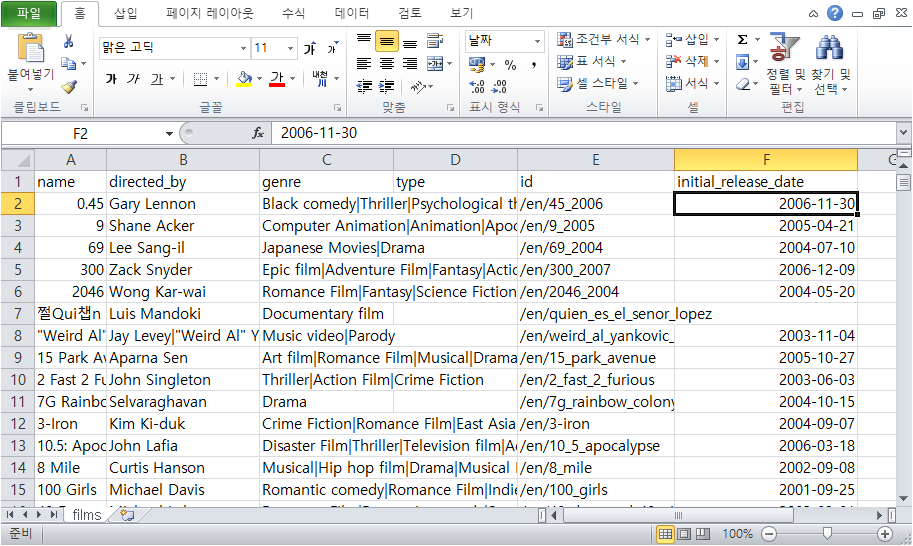
위 그림에서 id, name, menu, cat 등의 필드 명이 출력되는 것을 볼 수 있다.
이번에는 전체 필드가 아닌, 이 필드 중 cat 필드에 있는 값을 검색한다.
특정한 필드의 특정한 값을 검색할 경우(Field Searches)에는 cat:electronics와 같이 필드명을 콜론으로 구분해서 사용한다.
curl http://localhost:8983/solr/techproducts/select?q=cat:electronics
electronics으로 검색했을 때는 14건이 검색되었지만,
cat:electronics으로 cat필드에 대해서 검색했을 때는 12건이 검색된다.
여러 개의 단어로 검색 하는 구절 검색(Phrase Search)은 쌍따옴표("")를 이용한다.
먼저, SDRAM Unbuffered 로 검색하면, 4건이 검색된다.
http://localhost:8983/solr/techproducts/select?q=SDRAM%20Unbuffered
그리고, "SDRAM Unbuffered"로 검색하면 3건이 검색된다.
http://localhost:8983/solr/techproducts/select?q=%22SDRAM%20Unbuffered%22
쌍따옴표("" %22) 없이 검색하면
구절내의 단어를 분리해서 입력한 단어 2개 중 하나라도 있으면 출력한다.
일종의 OR 검색이 실행된 것이다.
쌍따옴표를 사용할 경우에는 해당한 구절이 있는 문서만 출력한다.
Solr 예제의 마지막은 결합 검색(Combining Searches)이다.
electronics music 로 검색하면
http://localhost:8983/solr/techproducts/select?q=electronics%20music
32건의 문서가 검색된다.
앞서의 예제처럼 electronics이 있거나(OR) music 이 있는 문서가 검색 된 것이다.
+electronics +music으로 검색하면 1건이 검색된다.
http://localhost:8983/solr/techproducts/select?q=%2Belectronics%20%2Bmusic
electronics과 music이 있는 문서만 검색 된 것이다.
즉, electronics가 있고(AND) music이 있는 문서가 검색된 것으로 일종의 AND 검색이 된 것이다.
이번에는 electronics -music 로 검색하면 13건이 검색된다.
electronics가 있지만 music 이라는 단어가 없는(-) 문서만 검색된다.
이상의 내용은 Solr의 기본 예제에 있는 내용으로,
전체 필드를 대상으로 한 결합 검색식을 필드에 적용해서 응용할 수 있다.
cat:electronics cat:music 으로 검색하면, 12건의 결과가 검색된다.
cat 필드에 electronics가 있거나 music 이 있는 데이터가 조회되는 것이다.
cat:electronics cat:music 은 cat:electronics OR cat:music 으로 사용할 수 있다.
http://localhost:8983/solr/techproducts/select?q=cat%3Aelectronics%20cat%3Amusic
http://localhost:8983/solr/techproducts/select?q=cat%3Aelectronics%20OR%20cat%3Amusic
즉 앞서서 필드를 지정하지 않고, 전체 필드로 사용했던 검색식을 필드를 대상으로로도 사용할 수 있다.
+cat:electronics +cat:music 은 cat 필드에 electronics가 있고 music 이 있는 데이터로 1건이 검색된다.
+cat:electronics +cat:music 은 cat:electronics AND cat:music 로도 사용할 수 있다.
http://localhost:8983/solr/techproducts/select?q=%2Bcat%3Aelectronics%20%2Bcat%3Amusic
http://localhost:8983/solr/techproducts/select?q=cat%3Aelectronics%20AND%20cat%3Amusic
cat:electronics -cat:music 은 cat 필드에 electronics가 있지만 music 이 없는 데이터로 11건이 검색된다.
http://localhost:8983/solr/techproducts/select?q=cat%3Aelectronics%20-cat%3Amusic
이 외에 DMBS의 LIKE 문처럼 cat:elect* 을 사용해서 cat필드의 내용 중 elect으로 시작하는 단어가 있는 문서 14건을 검색할 수 있다.
이 예제는 와일드카드(*)로 부분 문자열 검색을 나타내기도 하지만, 앞서 설명에서 빠진 중요한 개념을 가진 예제이다.
앞서의 첫 이미지를 자세히 보면
cat 필드는 문자열 값을 여러 개 가진 배열 타입인 것을 알 수 있다.
측, cat 필드는 ["electronics", "hard drive"]로 두 개의 문자열(“”)을 가진 배열[]이다.
다른 필드는 필드에 하나의 값을 가지지만 cat과 features는 여러 개의 값을 가진 배열이다.
(필드 타입에 배열이 있다는 점을 기억해야 한다.)
그리고, 이상에서 사용한 검색식들은 cat 필드의 값 중에서 검색하고 하는 문자와 일치하는 것만 조회 했다.
cat: electronics은 배열에 저장된 값이 정확하게 electronics일 때만 조회 된 것이다.
cat:elect*으로 조회할 경우에는 "electronics and computer1", "electronics and stuff2"가 있는 것도 조회 되었다.
cat: electronics은 일치하는 값만 조회하기 때문에 이 결과가 조회되지 않았다.
| { "id":"3007WFP", "name":"Dell Widescreen UltraSharp 3007WFP", "manu":"Dell, Inc.", "manu_id_s":"dell", "cat":["electronics and computer1"], "features":["30\" TFT active matrix LCD, 2560 x 1600, .25mm dot pitch, 700:1 contrast"], "includes":"USB cable", "weight":401.6, "price":2199.0, "price_c":"2199.0,USD", "popularity":6, "inStock":true, "store":"43.17614,-90.57341", "_version_":1654893957917704192, "price_c____l_ns":219900 }, { "id":"VA902B", "name":"ViewSonic VA902B - flat panel display - TFT - 19\"", "manu":"ViewSonic Corp.", "manu_id_s":"viewsonic", "cat":["electronics and stuff2"], "features":["19\" TFT active matrix LCD, 8ms response time, 1280 x 1024 native resolution"], "weight":190.4, "price":279.95, "price_c":"279.95,USD", "popularity":6, "inStock":true, "store":"45.18814,-93.88541", "_version_":1654893957930287104, "price_c____l_ns":27995}] } |
Solr 예제에서는 설명되지 않았지만 루씬 검색식에 있는 예제에 정리된 범위(Range)가 있다.
범위는 많이 사용하는 검색식(Query)으로
price:[* TO 100]은 가격(price)이 100($) 이하인 것,
price:[100 TO 500]은 100~500 사이인 것,
price:[100 TO *] 100보다 비싼 것을 검색하는 검색식이다.
보다 자세한 것은 루씬 검색식을 참고 하면 된다.
이러한 검색식들은 구글의 검색식과 비슷하게 제공되고,
다양하게 제공되니 예제를 익히고 나서 Solr 문서의 내용을 잘 읽어보길 바란다.
'서버 > 검색엔진' 카테고리의 다른 글
| 검색 엔진, 챗봇 개발에 유용한 사전 (0) | 2020.02.16 |
|---|---|
| 1. Solr 예제 분석 - 설치 (1) | 2020.01.12 |
| 3. Solr 예제 분석 - 스키마(Schema) (0) | 2020.01.12 |
| 4. Solr 예제 분석 - DIH (0) | 2020.01.12 |
| 1. Solr로 만드는 단순 게시판: 각종 설치 (18) | 2017.08.24 |